Quickstart
Get started onboarding an engine
- Log into the Arthur Platform - https://platform.arthur.ai
- Create an account if you don't already have one - if you do this the wizard will walk you through onboarding your first engine
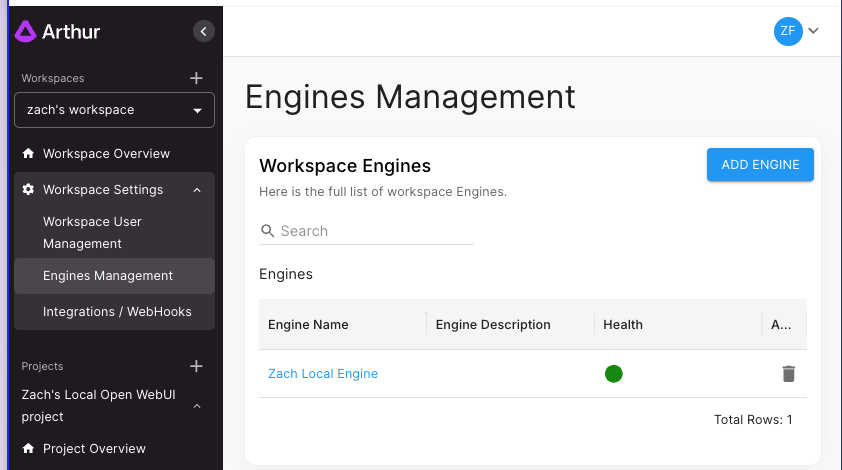
- Navigate to your Workspace's Engine Management page
- Navbar -> Workspace Settings -> Engines Management
- Click the "Add Engine" button
- Follow the instructions on the screen to launch an engine
- Wait for the engine to successfully connect
- Associate your engine with any projects that you want to create models in
Associating Engines with Projects
To ensure data security, Engines must be associated with Projects so that users accessing any Datasets linked to Models created by the Engine are governed using our Role Based Access Control policies.
RBAC policies are applied at the Project Level, and Engines are associated with Projects which allows Project Owners to control which Models and Datasets other users have access to.
Engines are associated with Projects when you onboard an Engine, but you can also later update Project associates by:
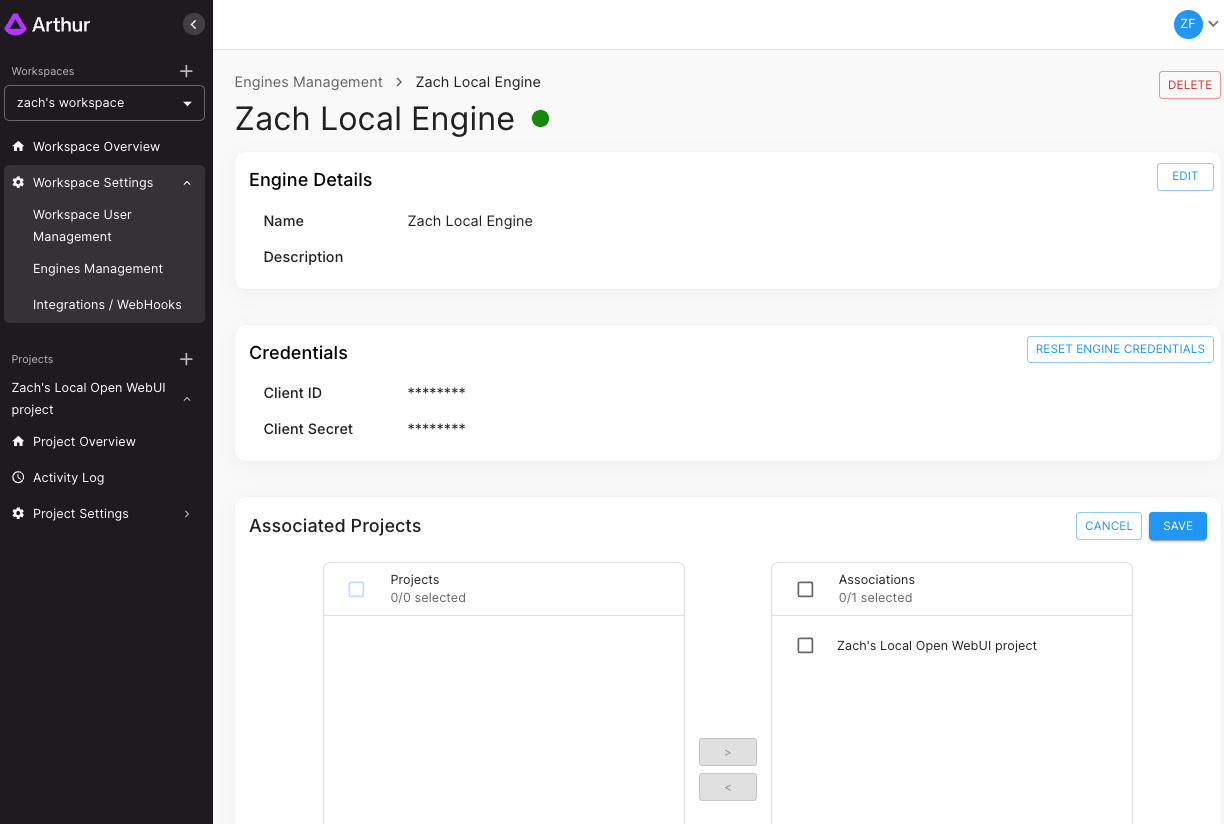
- Navigate to your Workspace's Engine Management Page
- Navbar -> Workspace Settings -> Engines Management
- Click the Engine you want to use
- Click the "Manage" button under the Associated Projects
- Add any Projects you want to associate the Engine with - the Projects should now show on the right-hand side of the view
- Click Save
Updated over 1 year ago
Did this page help you?