
Creating Arthur Model Object
Now that we are ready, we can start onboarding a model to Arthur. This page is a walkthrough of creating an ArthurModel object to monitor your ML model.
TL;DR
An ArthurModel object sends and retrieves data important to your deployed ML system. The ArthurModel object is separate from the trained underlying model and makes predictions; it is a wrapper for the underlying model to access Arthur platform functionality.
The general steps for creating an ArthurModelObject are as followed:
- Creating a production-ready ML model
- Prepare your model schema/ reference dataset for Arthur:
- Define build out and save your Arthur model object
A quick overview of the code needed can be seen below.
arthur_model = arthur.model(partner_model_id=f"CreditRisk_Batch_QS-{datetime.now().strftime('%Y%m%d%H%M%S')}",
display_name="Credit Risk Batch",
input_type=InputType.Tabular,
output_type=OutputType.Multiclass,
is_batch=True)
prediction_to_ground_truth_map = {
"prediction_1": 1
}
## Building out with Reference DataFrame
arthur_model.build(ref_df,
ground_truth_column="gt",
pred_to_ground_truth_map=prediction_to_ground_truth_map
non_input_columns=['age','sex','race','education'])
arthur_model.save()
Create a Production Ready Model
The first step to onboarding a model to Arthur is to create a model ready for or already deployed to production. Since Arthur is model and platform agnostic, it does not matter how the model is built or where it is deployed.
Pre-Production Monitoring
Some teams use Arthur’s techniques or platform to evaluate models pre-production. This is definitely an option. However, the same sentiment remains that you need to have a finished model to onboard to Arthur and evaluate.
Creating Arthur Connection
To be able to send inference data to the platform, you will need to create a connection to not only your Arthur platform but also the model the inferences are being tracked for. Information about creating your API key and connecting to the Arthur platform/model objects can be found in the UI/Platform Guide.
Prepare Model Schema / Reference Dataset for Arthur
Teams are required to define the model's structure or schema. A model structure, otherwise known as an Arthur model schema, defines a wireframe for what Arthur should expect as inputs and outputs to your model. By recording essential properties for your model's attributes, including their value type and stage, this structure ensures that the proper default environment and metrics are built for your model in Arthur.
When you are onboarding a model, Arthur categorizes each attribute into a different Stage,
depending on the role of the attribute in the model pipeline:
| Attribute Stage | Description |
|---|---|
ModelPipelineInput | All the features the model uses to create a prediction. For tabular, these are the features that go into the model. These are the text or image inputs for text or NLP. |
PredictedValue | Output values (or predictions) that your model produces |
GroundTruth | Values you can provide to compare the model's outputs against performance metrics (commonly referred to as target or label) |
NonInputData | Any attributes that are not predictive features within the model but are additional metadata you would like to track. (i.e., protected attributes like age, race, or sex, or business-specific data like unique customer id) |
Attributes are analogous to the different columns that comprise your model's data. Each attribute has a value type: these can be standard types like int and str, or datatypes for complex models like raw text and images.
| Available Input Value Types | Allowed Data Types | Additional Information Required |
|---|---|---|
| Numerical | Integer, Float | |
| Categorical | Integer, String, Boolean, Float | Specified Available Categories |
| Timestamp | DateTime | Must be time zone aware |
| Text (NLP) | String | |
| Generative Sequence (LLM) | String | A tokens (and optional token likelihood) column is also required |
| Image | .jpg, .png, .gif | |
| Unique Identifier | String | |
| Time Series | List of Dictionaries with "timestamp" and "value" keys | Timestamps must be timezone aware DateTimes and values must be floats. |
As you log data over time with Arthur, the model schema is used to type-check ingested data. This prevents analytics from being skewed by scenarios like int values suddenly replacing float values causing silent bugs.
Arthur also records attribute properties in the model schema, like the range of possible values an attribute has in your data. These properties are used to understand your data’s high-level structure, not to strictly enforce that future attributes have these same properties.
Some key things to keep in mind when onboarding models schemas are:
- Verify Categories Listed: Verifying the available categories for categorical attributes is important. You want to ensure that all expected categories appear or are added to each attribute's list of possible categories. This is because these categories will be used to calculate drift metrics and appear for advanced segmentation within the UI. Other category values may be sent to the platform but will not be part of this functionality.
- Specifying Attribute Bounds: Teams can set specified attribute bounds for numerical attributes, such as minimum and maximum values. These are only used to make setting alert thresholds (i.e., data-bound alerts on inferences passing an acceptable maximum value) easier.
- High Cardinality Models (over 1000 unique attributes) : Arthur does not allow for high-cardinality models (i.e., models with many unique columns) with more than 1000 unique attributes.
- High Cardinality Variables (over 1000 unique categories) : Arthur does not allow for high-cardinality variables (i.e., variables with many unique classes) with more than 1000 unique categories. This is more common for Non-Input metadata attributes than Model Input attributes. In these cases, we recommend manually overwriting
- High Cardinality Variables (over 50 unique categories) : Attributes do not need over 1000 unique categories to be considered high cardinality. An attribute with over 50 unique categories can be onboarded o Arthur, but there is some feature loss for this attribute. This attribute will not be used when calculating enrichments; this includes explainability, anomaly detection, and hot spots.
- Monitoring Specific Attributes for Bias: For attributes you know you want to track using Fairness Metrics, teams must designate those inferences for bias detection tracking. This is more explained later in the document here.
Typically, teams choose to infer this schema automatically from a reference dataset. However, a more in-depth look at how teams may choose to define schemas manually can be found here.
Selecting a Reference Dataset
A reference dataset is a representative sample of input features for your model. In other words, it is a sample of what is typical or expected for your model. Typically, teams onboard their model's training or validation data for reference.
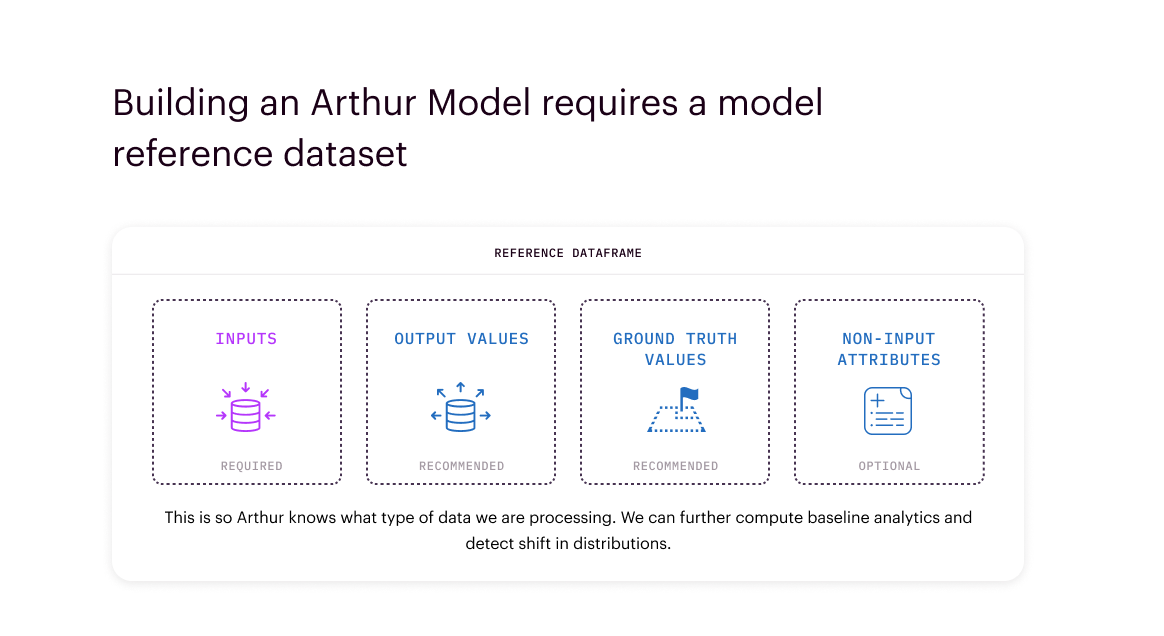
The reference dataset is a representative sample of the input features your model ingests. It is used to compute baseline model analytics. By capturing the data distribution you expect your model to receive, Arthur can detect, surface, and diagnose data drift before it impacts results. Examples of how reference data is structured for different model types can be found in the Model Input / Output Types section.
Selecting a Reference Dataset: We typically recommend using your training dataset as the reference. This is because there is no better dataset representation of the patterns your model has been built to learn than the actual dataset it learned on. However, teams do often choose to use other datasets as a reference. In particular when:
- The training dataset is oversampled / not representative of real-world data patterns: This commonly occurs when your positive predicted attribute is rare (i.e., tumor detection or credit card fraud).
- The training dataset is incredibly large: Reference datasets larger than 1GB can cause platform performance issues unless gradually onboarded in chunks. We recommend using a sample of your training or validation dataset for a larger dataset (typically, about 50,000 to 100,000 rows are sufficient to calculate drift metrics). It is important to ensure this is still representative of the entire dataset. In particular, we recommend including samples with extreme values included in the sample. For help onboarding in chunks or configuring your sample, please contact Arthur Support).
In these instances, we recommend using your validation dataset, or another evaluated dataset with representative patterns, as the reference.
Define Arthur Model Object
After cleaning the data, we need to start defining the Arthur model. To do this, we will need to provide both structural and user-defined information about the model:
arthur_model = arthur.model(partner_model_id=f"CreditRisk_Batch_QS-{datetime.now().strftime('%Y%m%d%H%M%S')}",
display_name="Credit Risk Batch",
input_type=InputType.Tabular,
output_type=OutputType.Multiclass,
is_batch=True)
User-Defined Information
Model Display Name
This name will appear for your model within the Arthur UI. Making this descriptive and intuitive is important, as it will be how most users search for and find your model. We recommend making this title description about that desired task your model is completing (i.e., Credit Card Fraud Classification). This is because you can create and track multiple model versions within the same display name.
Model Partner ID
Within Arthur, the Model Partner ID must be unique and cannot be duplicated across other models within your organization.
Often, teams may have an internal ID or identifying hash for their models. We do not recommend making this ID your model display name. As one, hashes are often hard to identify and search for without expert knowledge. And two, tracking multiple versions for a specific model use case is incredibly difficult. Instead, teams are encouraged to onboard that specific model's identifier as the Model Partner ID.
Using Timestamps Within Partner IDs
To avoid any confusion later, it is best practice to construct a partner_model_id with a timestamp embedded in the string, so that each time the model is onboarded, a new partner_model_id is generated.
Structural Information
This is information about the model's structure, i.e., how it runs. While Arthur is model agnostic, so it doesn't care how your model was built, we require you to specify some information so we can correctly set up your model's environment based on its specifications.
Data Type
Also known as the model input type, this is the type of data that the model will use to make predictions. The four possible data types are tabular, image, text, and time series.

Task Type
Also known as the model output type, this is the output your model will generate. The four possible model output types are multiclass (all classification), regression, object detection, and ranked list. This information is needed as the platform has to set up the correct default metric types within your model environment.

Batch v. Streaming
Next, teams should specify how they plan to send data to Arthur. We have two choices:
Batch: Lower frequency used (and monitored). Typical high inference load at a time
Streaming: High frequency of use (and monitoring). Typical lower inference load at a time
So, if you have users sending data frequently (e.g., daily), we recommend streaming models. Conversely, if you have users sending data infrequently (e.g., monthly), we'd recommend batching models for them. However, if you want guarantees about when metrics are calculated or alerts fire and cannot wait for the scheduled jobs to run, we recommend using batch models.
Another call-out is that batch models generate alerts by batch (i.e., a set threshold has been passed on average within a batch). Streaming models generate alerts by a designated lookback window (i.e., the average over the past day, week, etc.). More information on alerting can be found here.
Indicating a batch model means supplying an additional batch_id to group your inferences. Arthur will default to measuring performance for each batch rather than by the inference timestamps.
Prediction Mapping
Finally, when teams build out their Arthur model, they must specify a prediction mapping function.
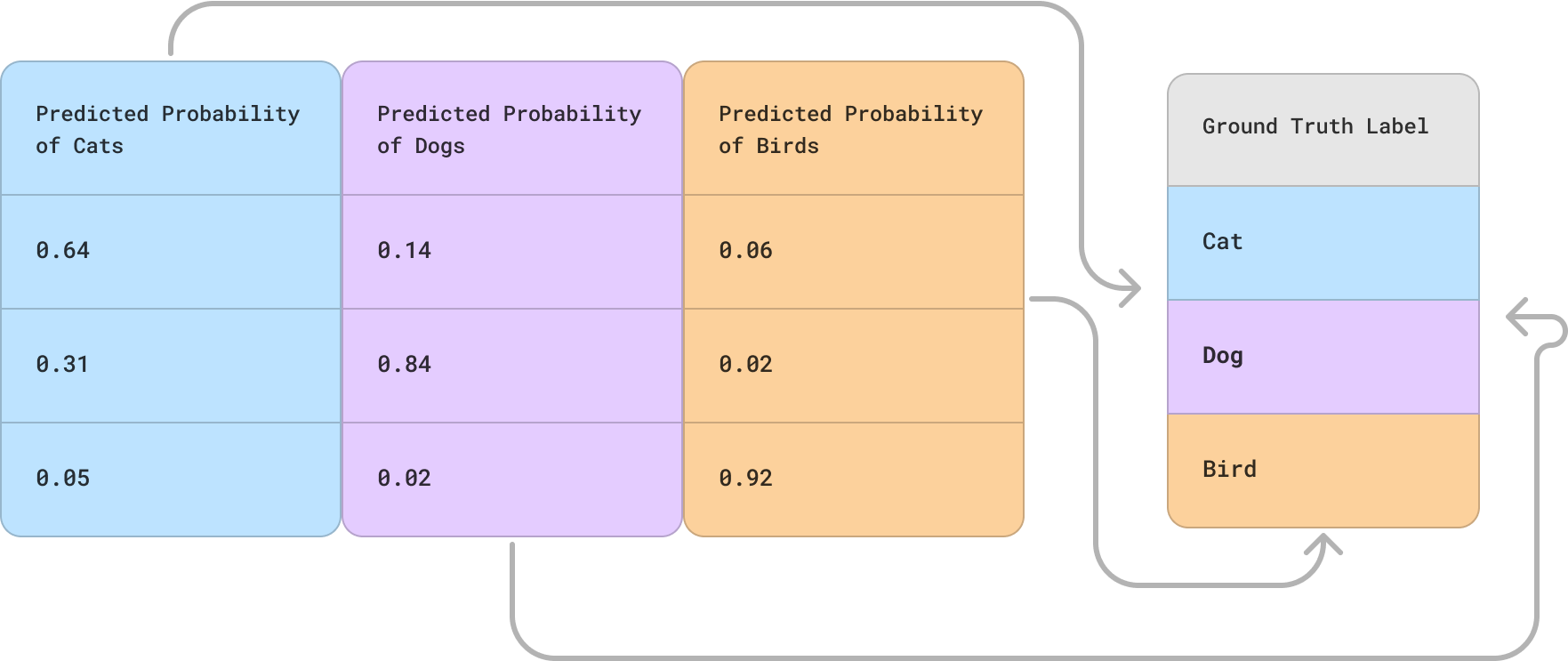
This ensures that Arthur correctly identifies predictive and ground truth classes when setting up the model's environment and calculating metrics. This mapping needs to identify which columns are prediction and ground truth but also map the labels within the columns to one another.
Examples of each model type's prediction mapping can be found in its Model Input / Output Types section.
Register Arthur Model Object
The simplest method of registering your attributes is to use the ArthurModel.build() function parses a Pandas DataFrame of your reference dataset containing inputs, metadata, predictions, and ground truth labels. In addition, a pred_to_ground_truth_map is required, which tells Arthur which of your attributes represent your model’s predicted values and how those predicted attributes correspond to your model’s ground truth attributes.
## General Format Example
## pred_mapping = {"model_inputs" :"model_outputs"}
# Map our prediction attribute to the ground truth value
# This tells Arthur that in the data you send to the platform,
# the `predicted_probability` column represents
# the probability that the ground-truth column has the value 1
prediction_to_ground_truth_map = {
"prediction_1": 1
}
## Building out with Reference DataFrame
arthur_model.build(ref_df,
ground_truth_column="gt",
pred_to_ground_truth_map=prediction_to_ground_truth_map)
Examples of each model type's mapping can be found within their specific Model Input / Output Types descriptions.
Non-Input Attributes (Optional)
Many teams want to track and monitor performance around metadata related to their model but are not necessarily model inputs or outputs. These features can be added as non-input attributes in the ArthurModel and must be specified in this build function.
# Specifying additional non input attributes when building a model.
# This tells Arthur to monitor ['age','sex','race','education']
# in the reference and inference data you send to the platform
arthur_model.build(
reference_df,
ground_truth_column='ground_truth_label',
pred_to_ground_truth_map=pred_to_ground_truth_map,
non_input_columns=['age','sex','race','education']
)
Verify Model and Onboard to Arthur
As mentioned above, your model schema can't be updated after you've saved your Arthur model object. For this reason, many teams choose to review their model schema before sending it to the platform. This can be done in the SDK with
arthur_model.review()
This creates a dataframe that contains all the information about the model schema. An example can be shown below:
After reviewing everything, teams can save their model to Arthur. This is done with the command below.
arthur_model.save()
Once you call arthur_model.save()Arthur will handle creating the model and provisioning the necessary infrastructure to enable data ingestion for this model. If model creation fails, you may try re-saving the model or contact support if the problem persists.
(Optional) Monitoring Attributes for Bias
For some of the attributes in your model, you may want to pay particular attention to how your model’s outputs are potentially different for each subpopulation of that attribute. We refer to this as monitoring an attribute for bias.
When you set up to monitor a PipelineInput or NonInput attribute for bias enables using Fairness Metrics for those attributes within your model UI.
Enable Monitoring for Bias Before Sending Inferences
You must enable monitoring attributes for bias before sending inferences to the platform.
Based on whether the attributes of interest are categorical or continuous, you can follow the steps below for each attribute of interest you'd like to monitor for bias.
Categorical Attributes
For a categorical variable, each possible level of the attribute will be treated as a distinct sub-population for analysis. For example, if you had an attribute for “Gender,” which comprised the three possible values Male, Female, and Non-Binary, then you would simply add the following to your model onboarding.
arthur_model.get_attribute("SEX", stage=Stage.ModelPipelineInput
).monitor_for_bias = True
Continuous Attributes
For a continuous variable, you need to break the continuous range into a fixed number of groupings so that we can create sub-populations. You can do this by providing cutoff thresholds for each grouping. For example, if we have a continuous attribute called AGE, we can create three age brackets, such as < 35, 35 - 55, and > 55. We create these groups by providing the upper-cutoff values for each group.
arthur_model.get_attribute("AGE", stage=Stage.ModelPipelineInput
).monitor_for_bias = True
arthur_model.get_attribute("AGE", stage=Stage.ModelPipelineInput
).set(bins = [None, 35, 55, None])
Updated over 1 year ago
Move onto enabling enrichments in Arthur or learn more about specifics around model attributes and stages