
Hot Spots
Automatically illuminate underperforming segments in your data
When a system has high-dimensional data, finding the right data input regions, such as troubleshooting, becomes a difficult problem. Hotspots automate identifying regions associated with poor ML performance to significantly reduce the time and error of finding such regions. Arthur Scope utilizes a proprietary tree-based algorithm to search out areas of underperformance and explain them through human-understandable language. Find out more about the algorithm here:
Hot Spots in Arthur Scope
Hot Spots are under the Insights tab in your Arthur Model dashboard.
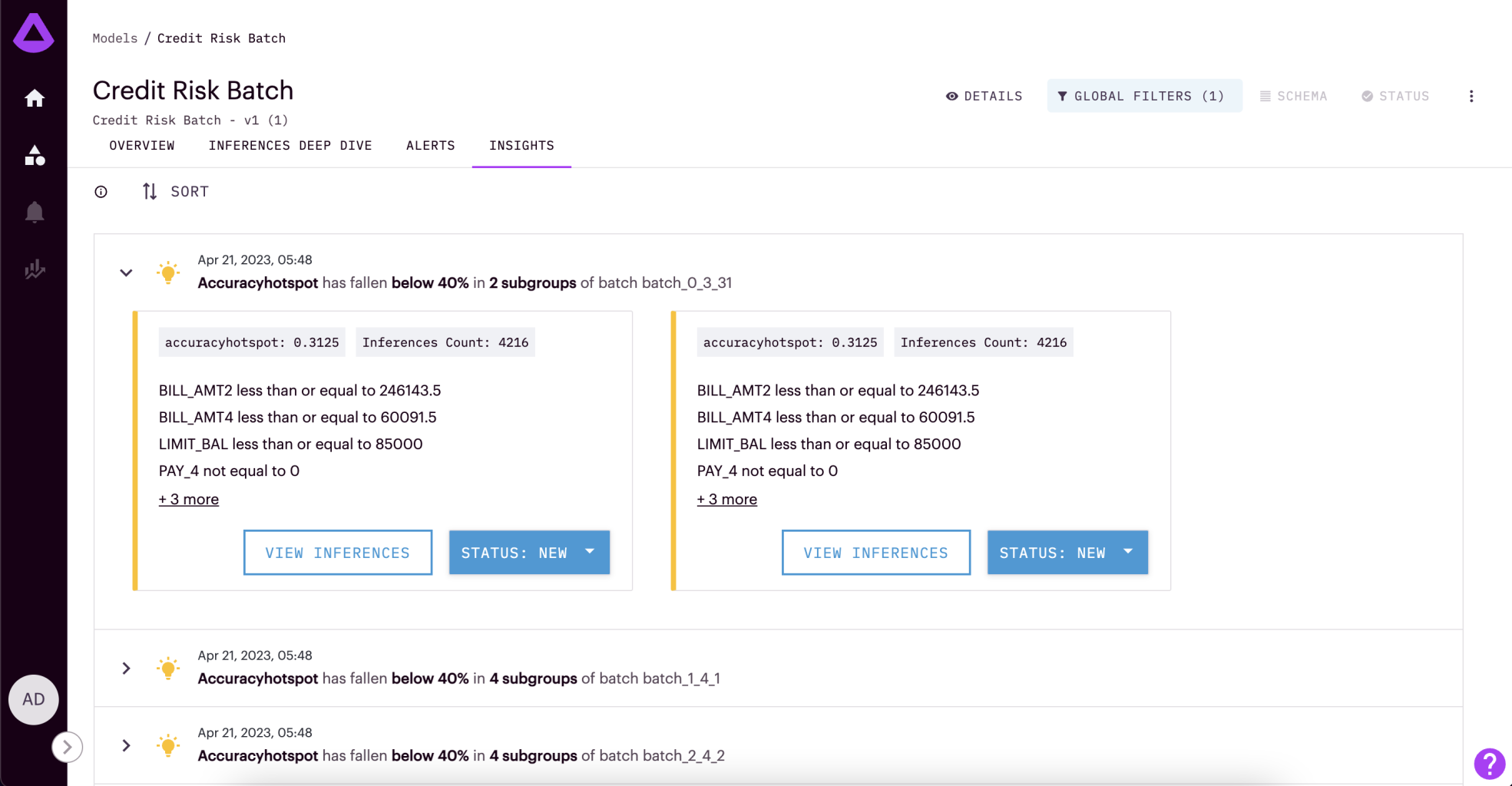
Time Intervals: To highlight when underperformance occurred, Hot Spots are calculated for specific segments of time. For batch models, this is every batch. For streaming models, this is every 7 days.
Performance Threshold: In the UI, Hot Spots we currently only have accuracy Hot Spots available to detect performance under 40%.
Subgroups: The segments of data that have been identified as underperforming in each Hot Spot
Clicking on a Hot Spot
Subgroup Performance: The accuracy rate for this subgroup of data
Inference Count: How many inferences were included in this subgroup
Subgroup Rules: The rules that define the inferences included in this subgroup. Rules are set up to incorporate any metadata sent to Arthur, not just model features (i.e., can include any non-input attributes provided to Arthur). To ensure actionable Hot Spots, we allow a maximum of 7 rules.
View Inferences Button: Click on this button to go to the inferences deep dive page automatically filtered to match the rules within this subgroup for continued exploration
Status Button: Change the status from New to Acknowledged to alert other team members that you have evaluated this hot spot.
Available Arthur Schemas
Currently only available for Tabular binary and multiclass classification models within Arthur.
Understanding the Algorithm
To learn more about the algorithm used for Hot Spots. Please refer to the Arthur Algorithms documentation section.
Updated over 1 year ago
Learn more about enabling enrichments for your model in the Model Onboarding section. Otherwise, click on Explainability to learn about another type of enrichment.