
Token Likelihood
There are currently no standard post-hoc explainability techniques for generative text (or token sequence) models. However, teams looking to better understand their models' outputs can turn to Token Likelihood for insights.
Token Likelihood Availability by LLM Type
Teams may choose from a number of LLM providers (OpenAI, Anthropic, Cohere, etc) to build their model. All of these model types can be monitored with Arthur. However, not every LLM provider allows the option for outputting token likelihood. To track token likelihood in Arthur, teams must provide token likelihood outputs from an LLM that outputs them.
Understanding Token Likelihood
The token likelihood is a number between 0 and 1 that quantifies the model’s level of surprise that this token was the next predicted token of the sentence. If a token has a low likelihood (close to 0), it means that the model is more unsure about selecting this token. While a likelihood close to 1 indicates that the model is very confident in predicting this token.
For example, if I was writing the sentence: I need to pack my backpack and ____

We can see from this example how token likelihood works. Textbooks is seen as a much more likely next word for the sentence than other terms like umbrella.
In LLM models, each token predicted has a likelihood.
What it looks like in Arthur
In Arthur Scope, Token Likelihood can be found, per inference provided for, in the Inferences Tab or the UI for text token sequence types.
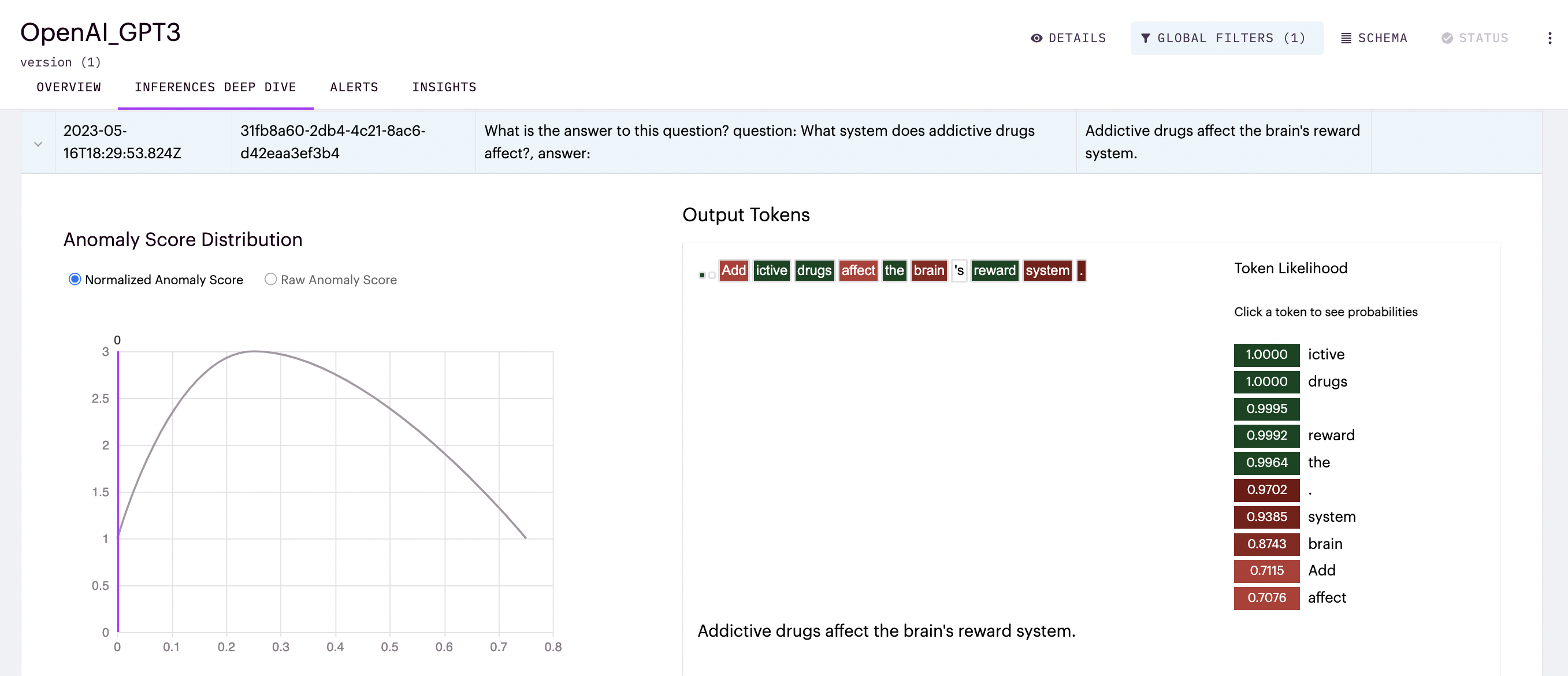
The color of tokens ranges from green to red, with bright green being the most likely and bright red being the least for tokens in each inference.
Tracking Likelihood Metrics as Performance
We've seen how looking at individual inferences Token Likelihood can provide insight into a single prediction, but what if we wanted to use likelihood to assess trends?
Average Token Likelihood
The average token likelihood is created for each inference by taking the average likelihood score of predicted tokens in that inference. The average of these scores is then calculated for inferences within whatever time interval specified, i.e., daily, weekly, snapshot, etc.
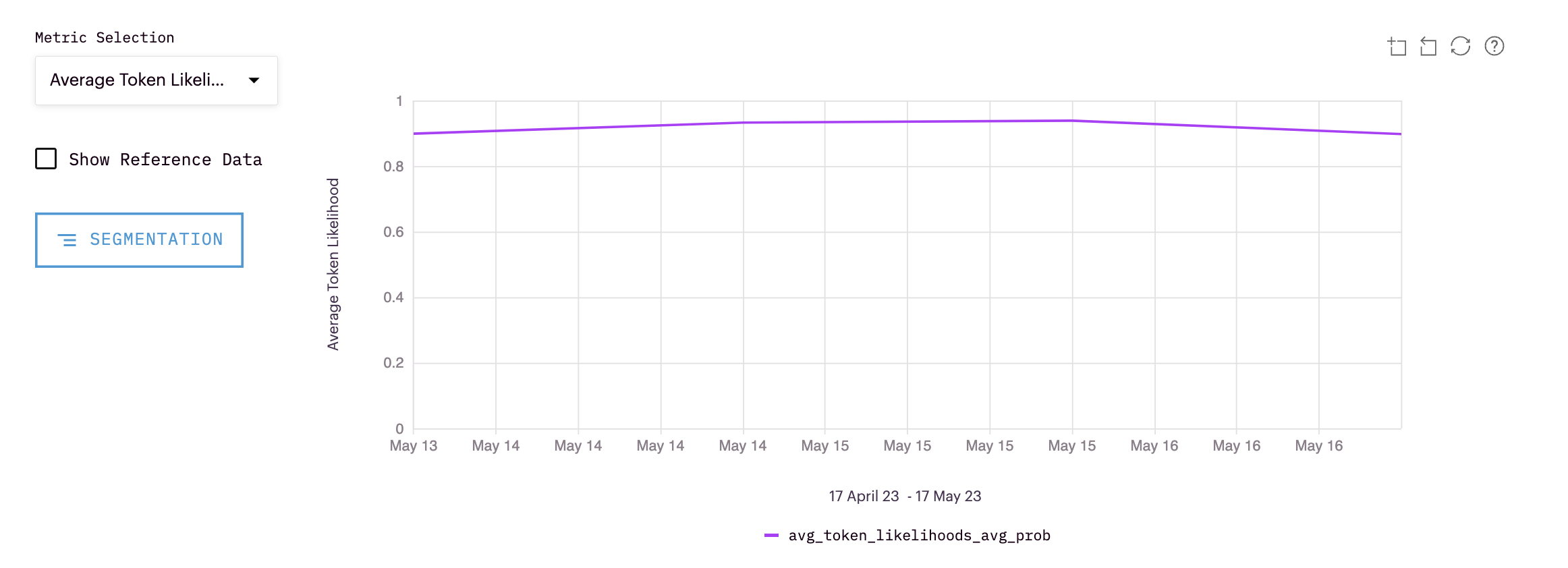
The average token likelihood is a way to evaluate how confident your model is in its overall predictions. By tracking this over time, teams can better track this confidence.
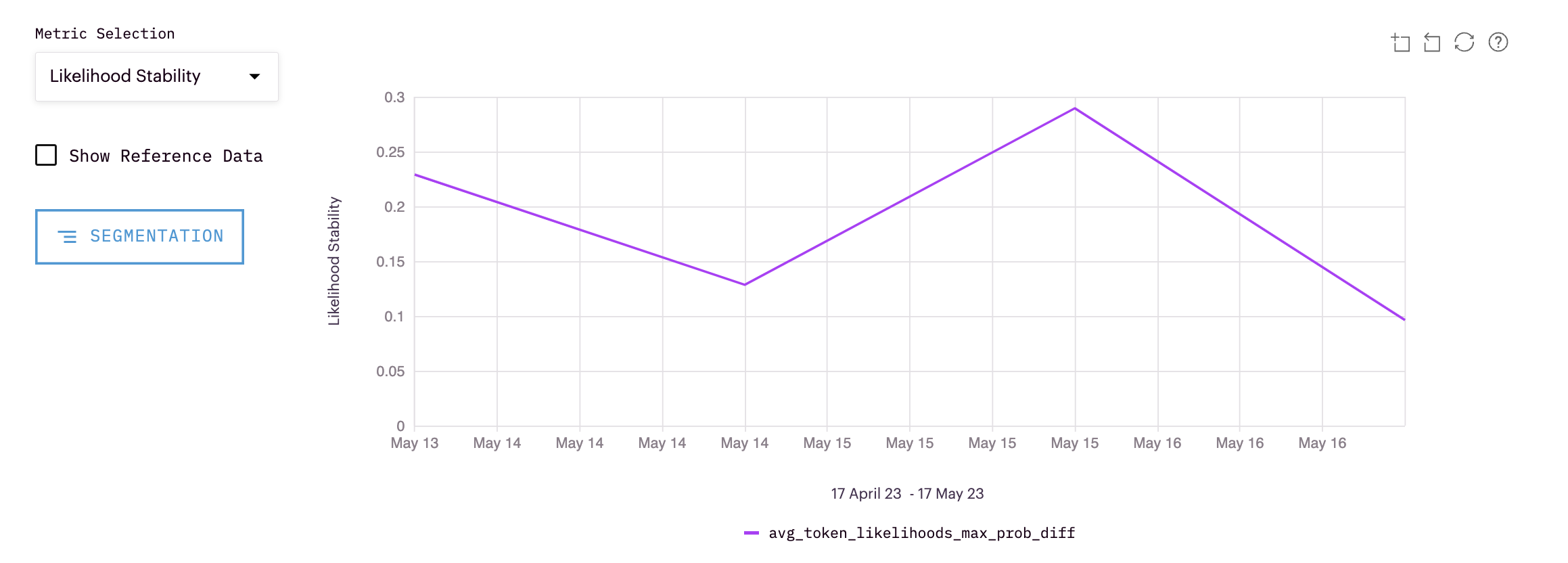
Likelihood Stability
Likelihood stability looks at how stable your likelihood is between tokens for each inference.
Updated over 1 year ago