
Data Preparation for Arthur
What type of data do I need to prepare for the Arthur platform ?
At a high level, teams often want to know what they need to set up to onboard Arthur before starting the onboarding process. As shown below, the assets teams need to prepare to use Arthur are directly related to how they want to use Arthur for their models.
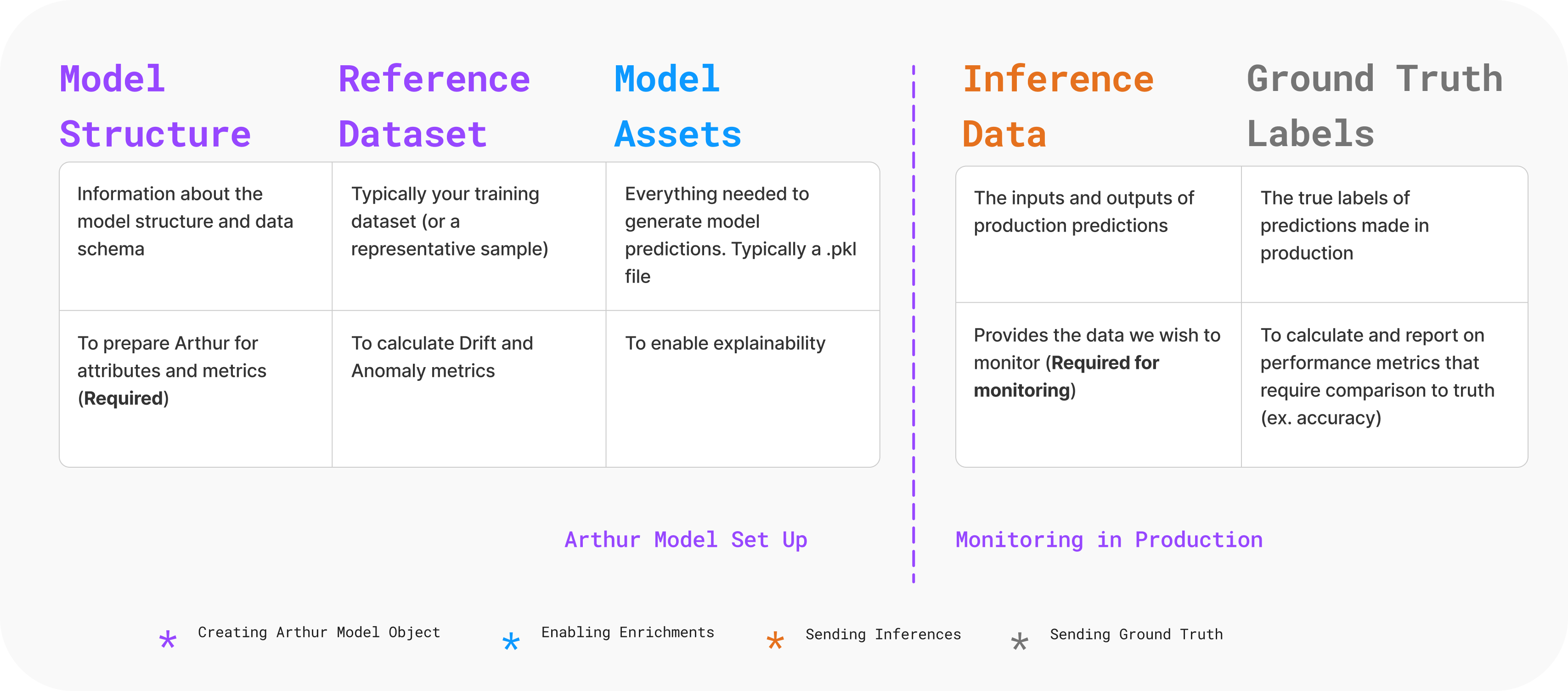
We can see that the only assets required to monitor inferences actively are your model structure and inference data. However, teams that wish to use more aspects of the Arthur platform than seeing inputs and outputs need to onboard/send additional assets to Arthur.
Model Structure
A model structure, otherwise known as an Arthur model schema, defines a wireframe for what Arthur should expect as inputs and outputs to your model. By recording essential properties for your model's attributes, including their value type and stage, this structure ensures that the proper default environment and metrics are built for your model in Arthur.
Example model input and output
To define this wireframe, teams must provide either example model input and output data (as in a reference dataset) or define all model inputs (features) and outputs (predictions or ground truth) as well as their expected values. These values must be a type allowed by Arthur.
At a high level, these are the available Arthur Inputs:
| Available Input Value Types | Allowed Data Types | Additional Information Required |
|---|---|---|
| Numerical | Integer, Float | |
| Categorical | Integer, String, Boolean, Float | Specified Available Categories |
| Timestamp | DateTime | Must be time zone aware. Cannot be Null or NaN |
| Text (NLP) | String | |
| Generative Sequence (LLM) | String | A tokens (and optional token likelihood) column is also required |
| Image | .jpg, .png, .gif | |
| Unique Identifier | String | |
| Time Series | List of Dictionaries with "timestamp" and "value" keys | Timestamps must be timezone aware DateTimes and values must be floats. |
These are the available Arthur Outputs:
| Arthur Output Type | Allowed Data Types | Notes |
|---|---|---|
| Classification | Integer, Float | Cannot be Null or NaN |
| Regression | Integer, Float | Cannot be Null or NaN |
| Object Detection | Literal Array of Bounding Box Values | Cannot be Null or NaN |
| Generative Sequence Unstructured Text | String | Cannot be Null or NaN |
| Generative Sequence Token Likelihood | Array of Float Values | This is optional. Cannot be Null or NaN |
| Ranked List | List of Dictionaries with "item_id", "label", and "score" keys | "item_id" and "label" values must be strings, "score" value must be a float. "label" and "score" keys are optional. |
For more specific examples of troubleshooting onboarding for specific model input and output types, please refer to Registering Model Attributes Manually.
Map of Data Relationship
As well as information about how our model predictions relate to our ground truth attributes. This is used to help prepare the Arthur platform to calculate performance metrics correctly.
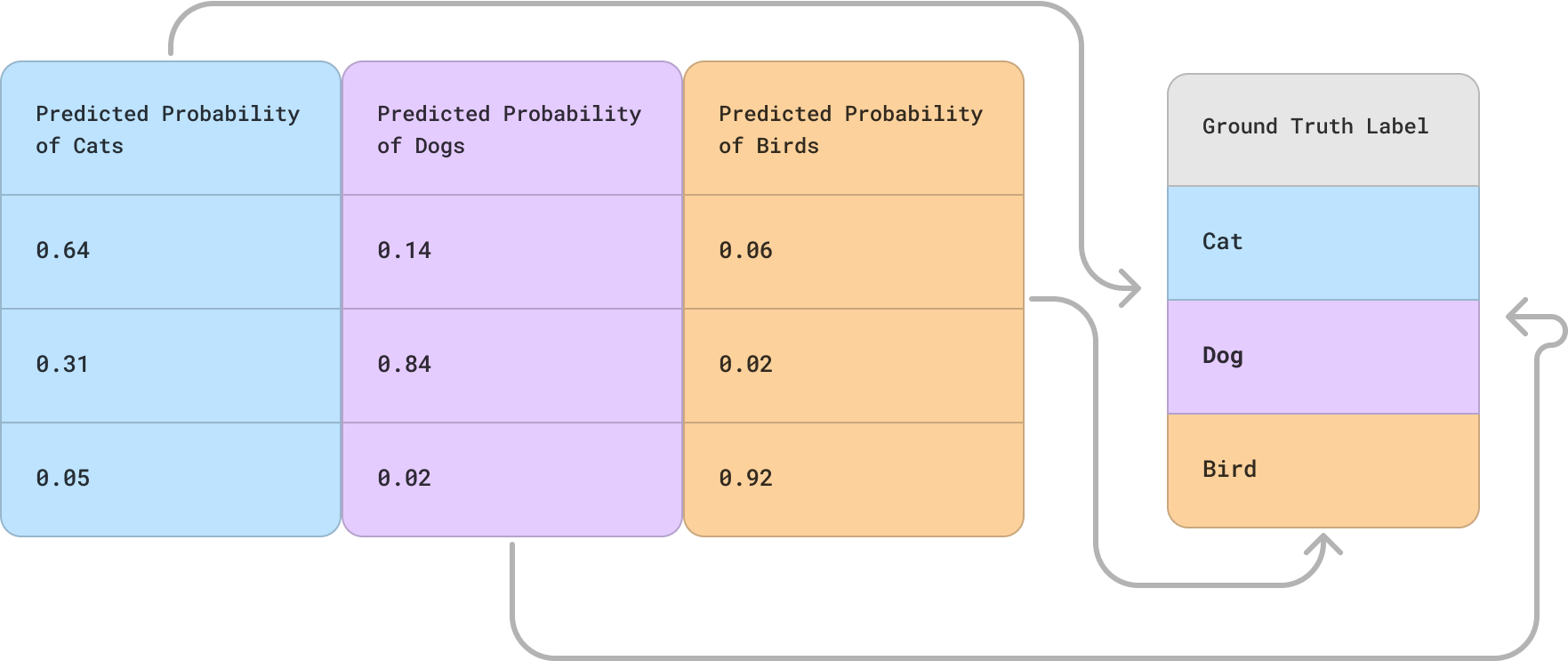
Teams can register this structure about their models manually ( Registering Model Attributes Manually). However, the most common way teams define their model structure in Arthur is by having it automatically inferred by onboarding their Reference dataset with the Python SDK.
Reference Dataset
A reference dataset is a representative sample of input features for your model. In other words, it is a sample of what is typical or expected for your model. Typically, teams onboard their model's training or validation data for reference.
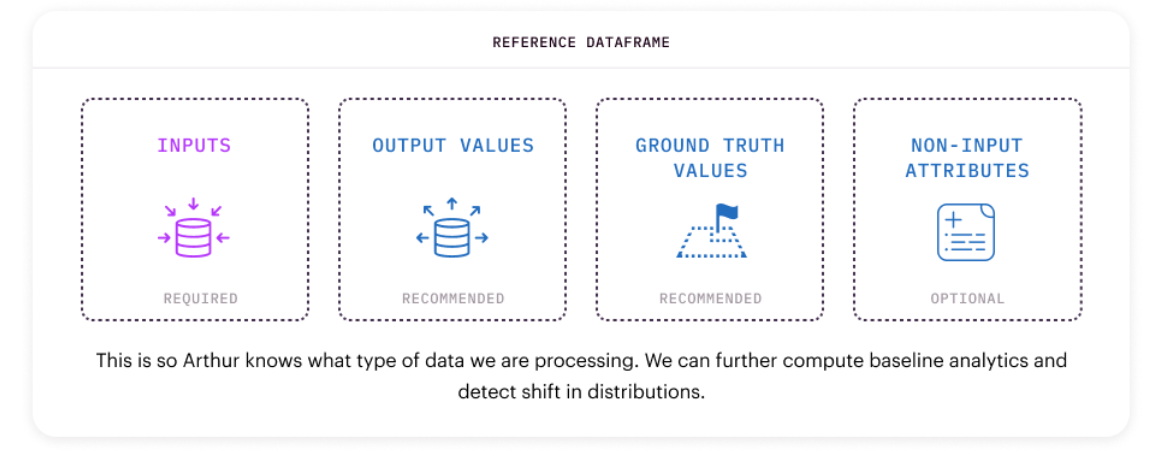
In the Arthur platform, your reference dataset provides the baseline for data drift and anomaly metrics. Therefore, for those techniques to appear, a reference dataset must be set for your Arthur model object.
The only required stage to be included in the reference dataset is ModelPipelineInput. But we also recommend including data from the PredictedValue, GroundTruth, and NonInputData stages so that Arthur can also measure drift in those attributes over time.
Note: As mentioned in the data drift metric section, univariate data drift metrics can be calculated in the Python SDK by comparing inferences to one another without a reference dataset.
For more information on best practices/guidelines for selecting your reference dataset, please refer to the Creating Arthur Model Object page.
Model Assets
Model assets are only required for teams that wish to enable explainability for their model. Explainability, as described better in the Explainability section, can be used to understand the model's decisions better. These assets are further described in (add explainability section), but they include:
- Requirements.txt File: a file containing all the requirements needed to run your predict function
- Model: the compressed runnable model used to generate predictions (typically .pkl format)
- Entrypoint Python File: this file contains your Python predict function that will be used to generate predictions to produce explanations
- Inputs: List
- Outputs: List
import …
model = load.model(‘pkl_model’)
## Python Predict Function
## takes in and returns a list
def predict(x):
return model.predict_proba(x)
Inference Data
For teams that want to use Arthur for the primary purpose of monitoring, it is essential to set up active monitoring of the data and predictions your model is running on in production. In Arthur, these rows of data are called inferences. Data associated with each inference might include (1) input data, (2) model predictions, and/or (3) corresponding ground truth.
Teams with the most success monitoring work to automate or create a consistent process for sending inferences to the platform.
Inference Ground Truth
While ground truth can be sent simultaneously as inference data, many ML models do not receive ground truth labels during prediction. In these instances, teams can set up a process to match ground truth in the platform with outside labels.

Note on sending large data to Arthur
While Arthur supports ingesting reference data, inferences, and ground truth labels, there are some constraints on ingestion that are worth being aware of. Clients are responsible for ensuring that data sent to Arthur respects these limits except for where called out below:
- Arthur's ingress proxy has a 4Gb limit on the size of any request payload that's made to Arthur. Requests which exceed this 4Gb limit will error out indicating that the body was too large.
- Arthur's ingestion-service (responsible for ingesting data) has a fixed amount of memory available. By default, this is 2Gb, but is configurable through the administrative interface or deployment scripts. Requests exceeding this limit may cause ingestion-service to run out of memory and crash.
- SDK users that are ingesting Images using
send_bulk_inferences,send_bulk_ground_truthsorset_reference_datawill have their files chunked so that they respect these limits.
- SDK users that are ingesting Images using
Updated over 1 year ago