
Explainability
Understand why your model is making decisions
Explainability is one of the core pillars of the Arthur Scope platform. Teams utilize explainability to build trust with valuable insights into how their ML models make decisions. They use it to explore patterns, investigate problems, and ensure compliance with explanations for their model outputs. Finally, they can use it to debug by understanding not only why predictions are being made but also evaluating how changes to model inputs change predictive outputs.
Levels of Explainability in Arthur UI
Explainability can be evaluated at multiple levels within the Arthur platform. These levels include:
Global Explainability (Tabular Models)
Global explainability in machine learning models refers to the ability to understand and explain a model's overall behavior and decision-making process across its entire dataset or population. Teams often use global explainability as a gut check to ensure that the features they consider the most important are the ones driving decisions.
Teams can also drive value from global explanations through interactions with other metrics within Arthur Scope. In the Arthur UI, for example, global explainability can be visualized in conjunction with a data drift of choice at the bottom of the Overview page.
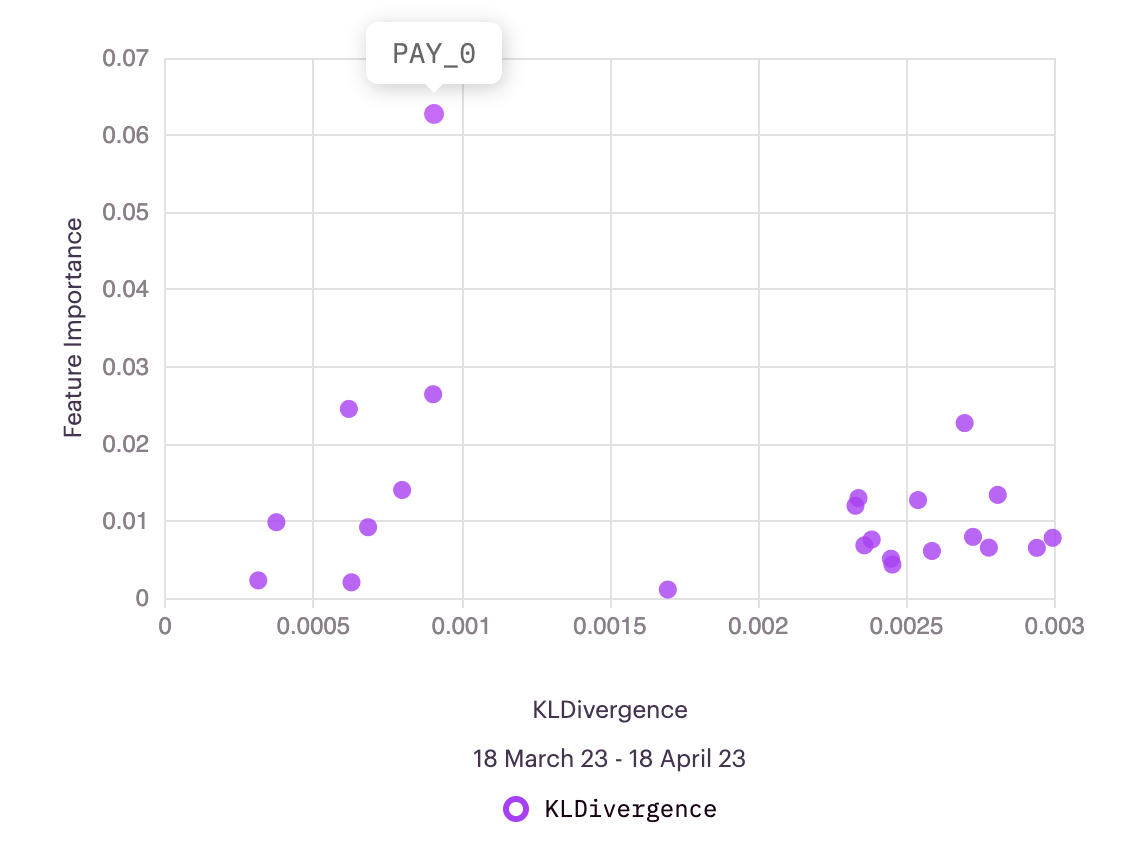
In this figure, we can see that Pay_0 is the most important feature.
Using explainability in conjunction with other metrics can help teams understand and debug models and drive actions such as model retraining or new feature/architecture exploration.
Global Explanations are an aggregate of local explanations
Within Arthur, global explanations are created by aggregating the absolute value of local explanations. The absolute value is taken because, as you will see in local explainability, features can positively or negatively impact whether or not a prediction is made. By taking the average absolute value of all local explanations, global explanations are a measure of feature impact (not necessarily positive or negative).
Local Explainability
Local explainability in machine learning refers to the ability to explain the reasoning behind a model's prediction for a particular instance or input. Teams can access local explainability for inferences within an Arthur Models Inference Tab.
Select Positive Predicted Attribute: Teams need to select a positive predicted attribute when running local explanations because it focuses the explanation on a specific prediction of interest. I.E., we are generating explanations for what causes that prediction to occur.
For example, in binary classification, this helps us read the explanation to understand whether the feature is driving the prediction for that class in a positive way or a negative way by driving the prediction for the other class instead. This is the same for multiclass models; however, unlike binary, for negative importance scores, we cannot attribute this negative importance to the other class. This is because there are more than two classes. It could be driving predictions to any other predicted class instead.
Tabular Inferences
We can visualize local importance scores for each model input feature for tabular inferences.
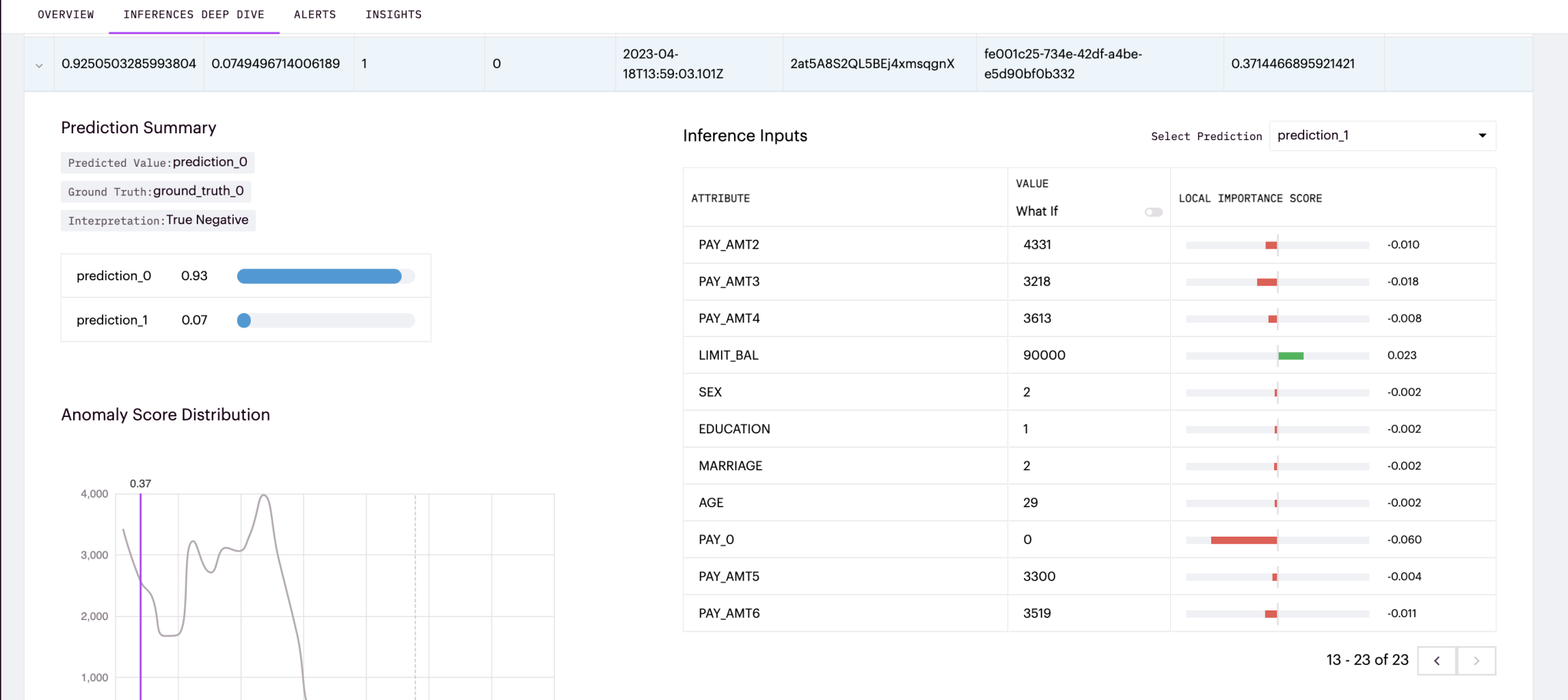
Here we can see
What If Capabilities
"What If" local explainability functionality refers to the ability to interactively explore and understand the impact of changing input features on a model's prediction for a particular instance or input. To utilize What-Ifs for a specific inference, a user needs to toggle on the "What-If" functionality in the Arthur UI for that inference. Then they can change any feature and evaluate how it changes the model's predictions or relative importance scores.
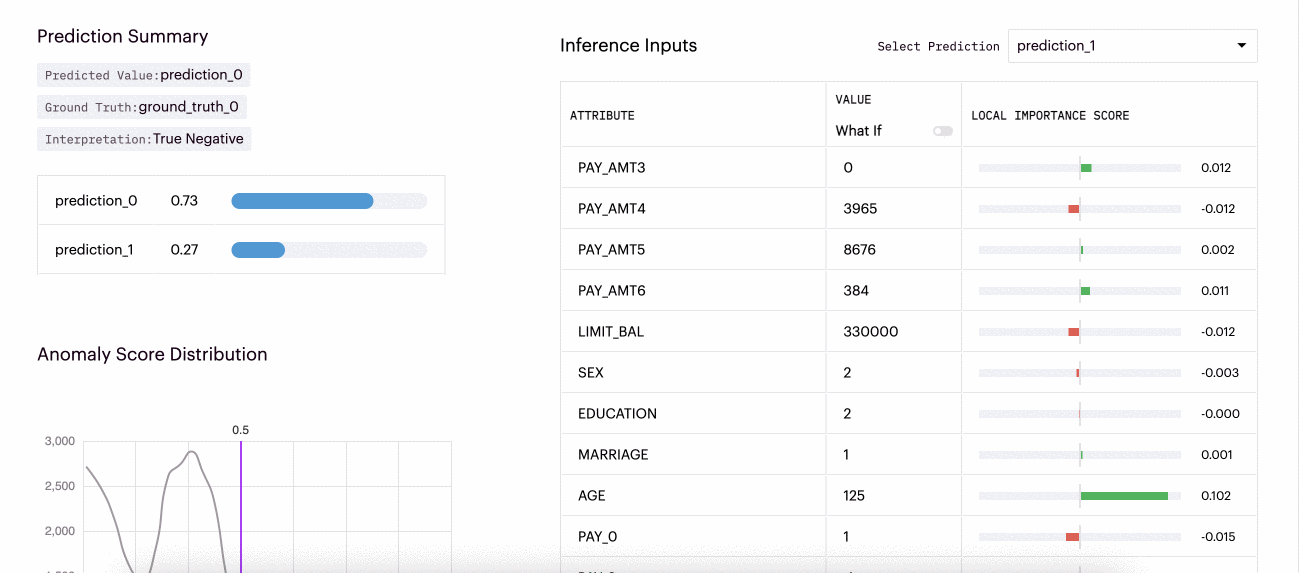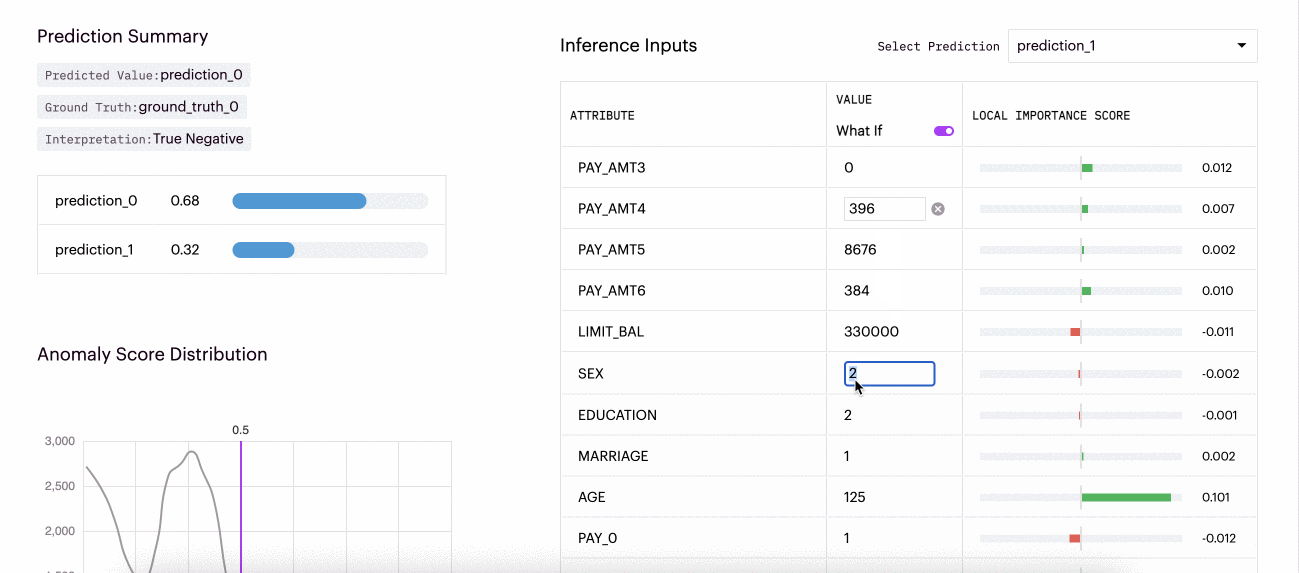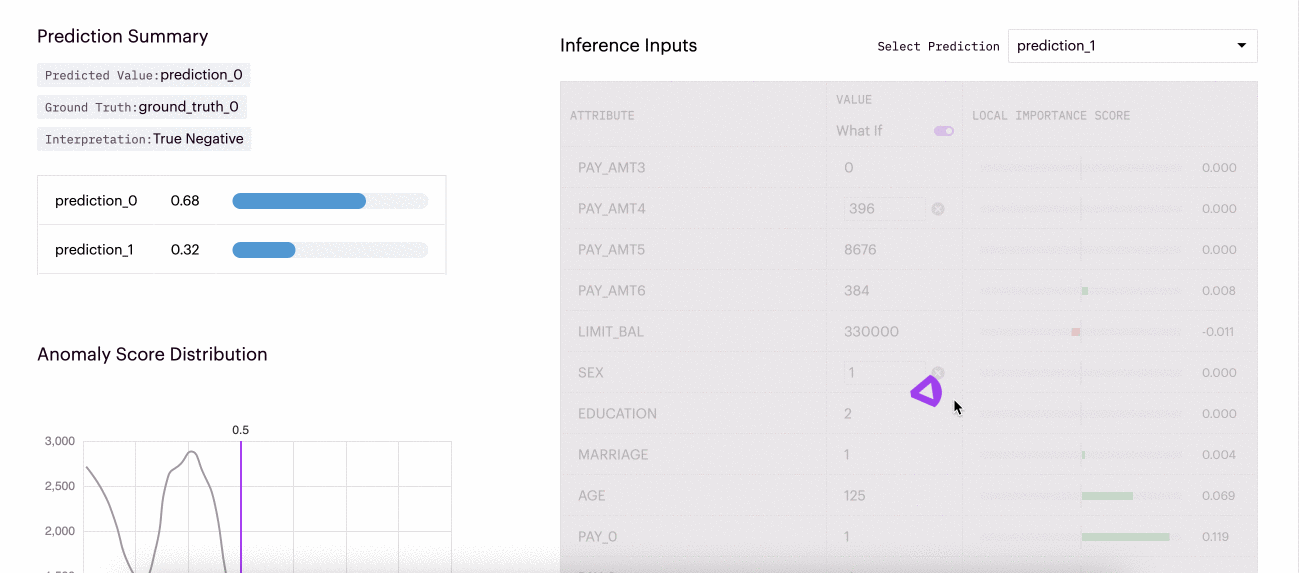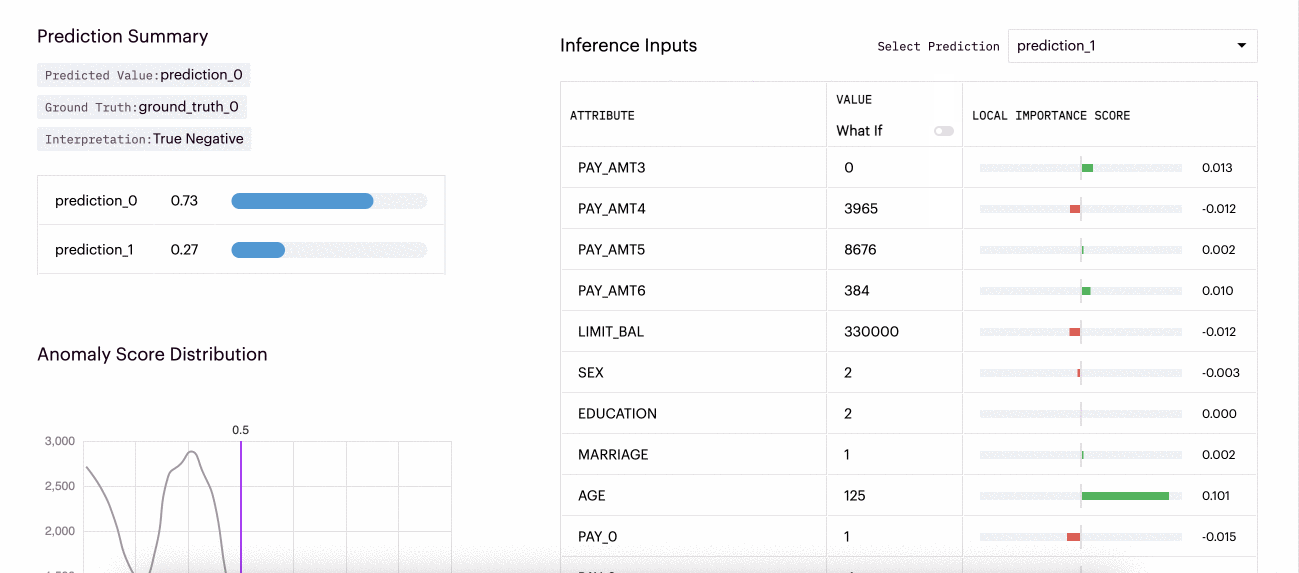
This example shows how different inputs for this inference affected the local importance scores for the inference and the predicted probabilities.
Text Inferences
For text models, teams can visualize the words that drive predictions. Note: Explainability is only available for classification and regression text models. We do not currently have explainability functionality for generative text models. Instead, teams can look into Token Likelihood for generative models.

In this example, we can see that the model mispredicted consult_history_and_phy instead of urology. We can use explainability to examine the top tokens that drove this misprediction between the two classes.
Is Bag of Words: Bag of words is a text representation technique in natural language processing that converts a document into a collection of its words. When "Is Bag Of Words" is turned on, explainability scores are calculated per word - not considering where duplicate words are placed in the text. However, when it is turned off, each duplicate word is treated as a unique token. So, placement in the text is taken into consideration.
Tokenization: Features for text input models are often called tokens. As described further in the Text input section, Arthur default to create word-based tokens based on whitespace. If whitespace does not make sense in your use case, make sure to set up a different tokenization when enabling explainability.
Image Inferences
For image classification/regression models, teams can visualize the segments of the image that drive different predictions.
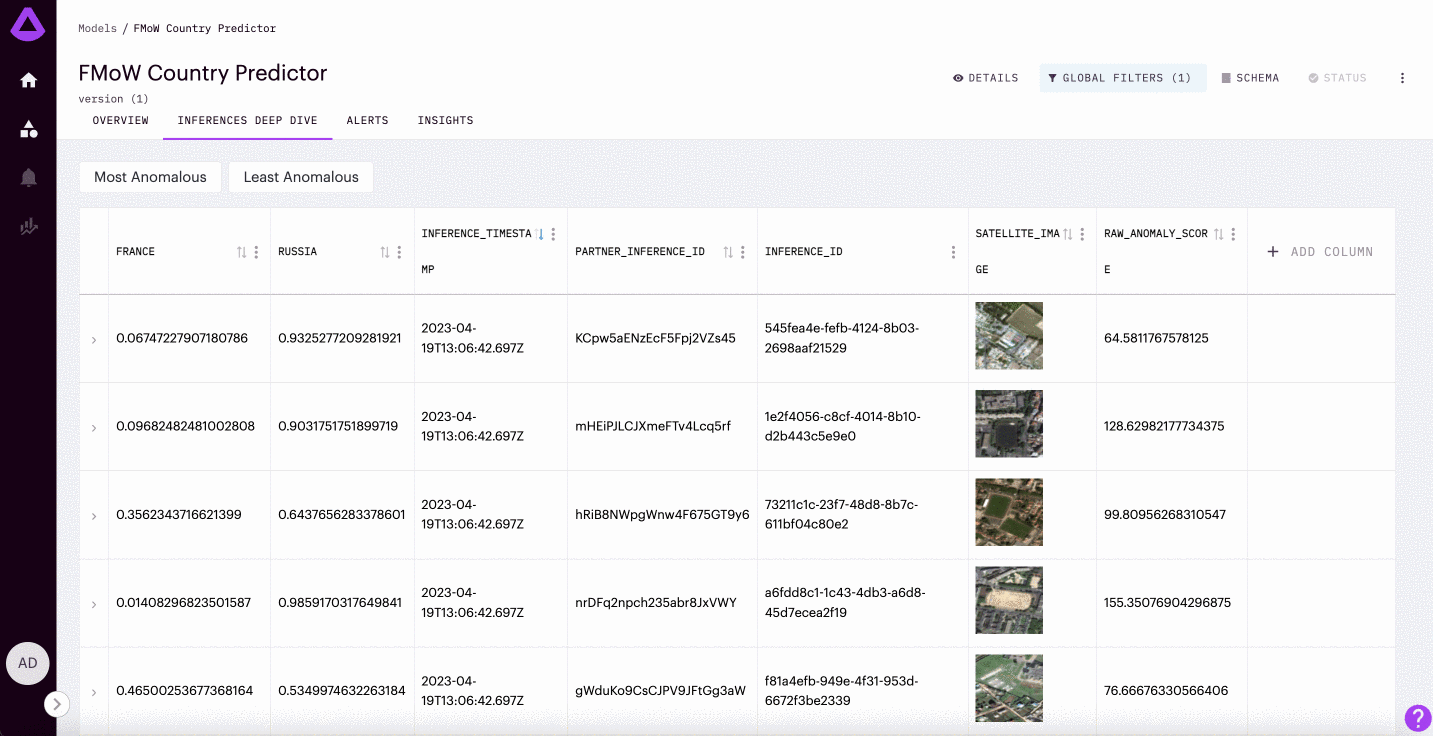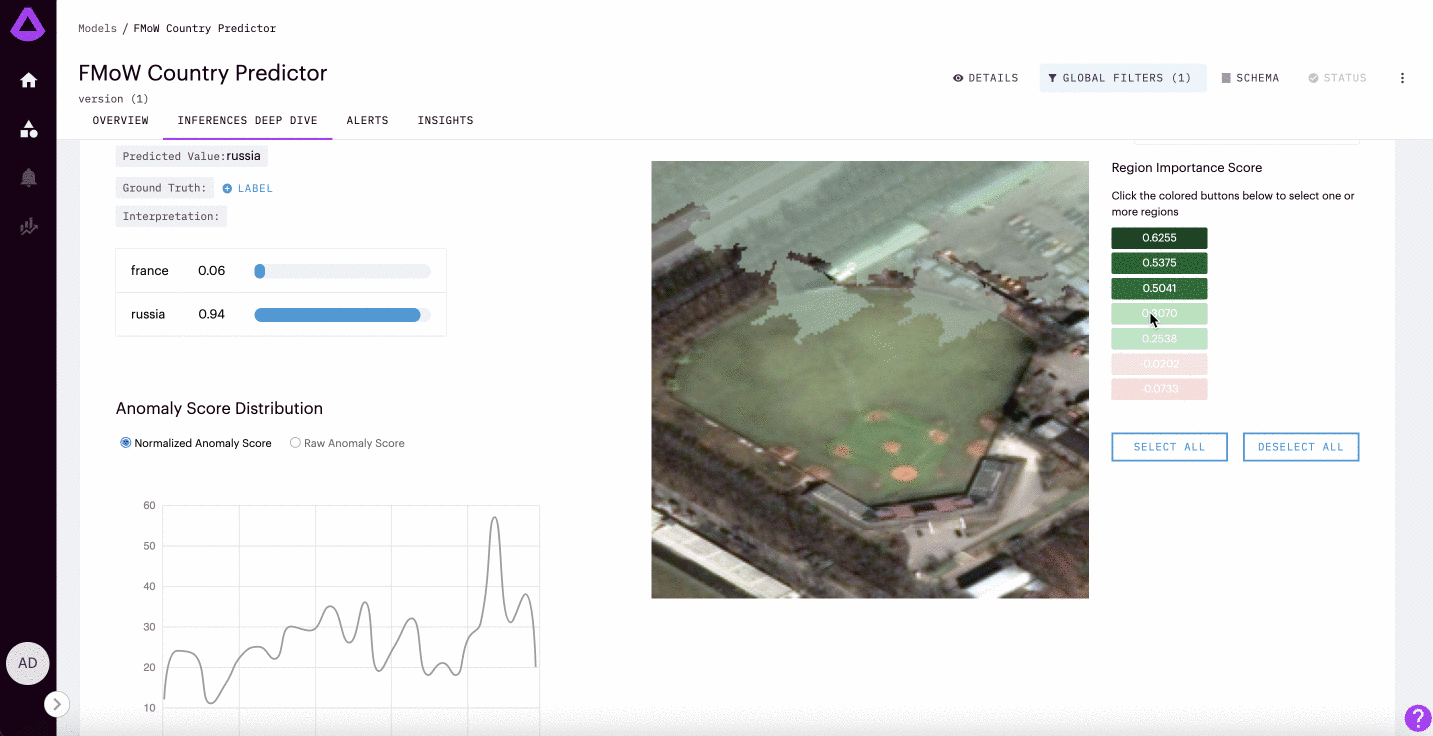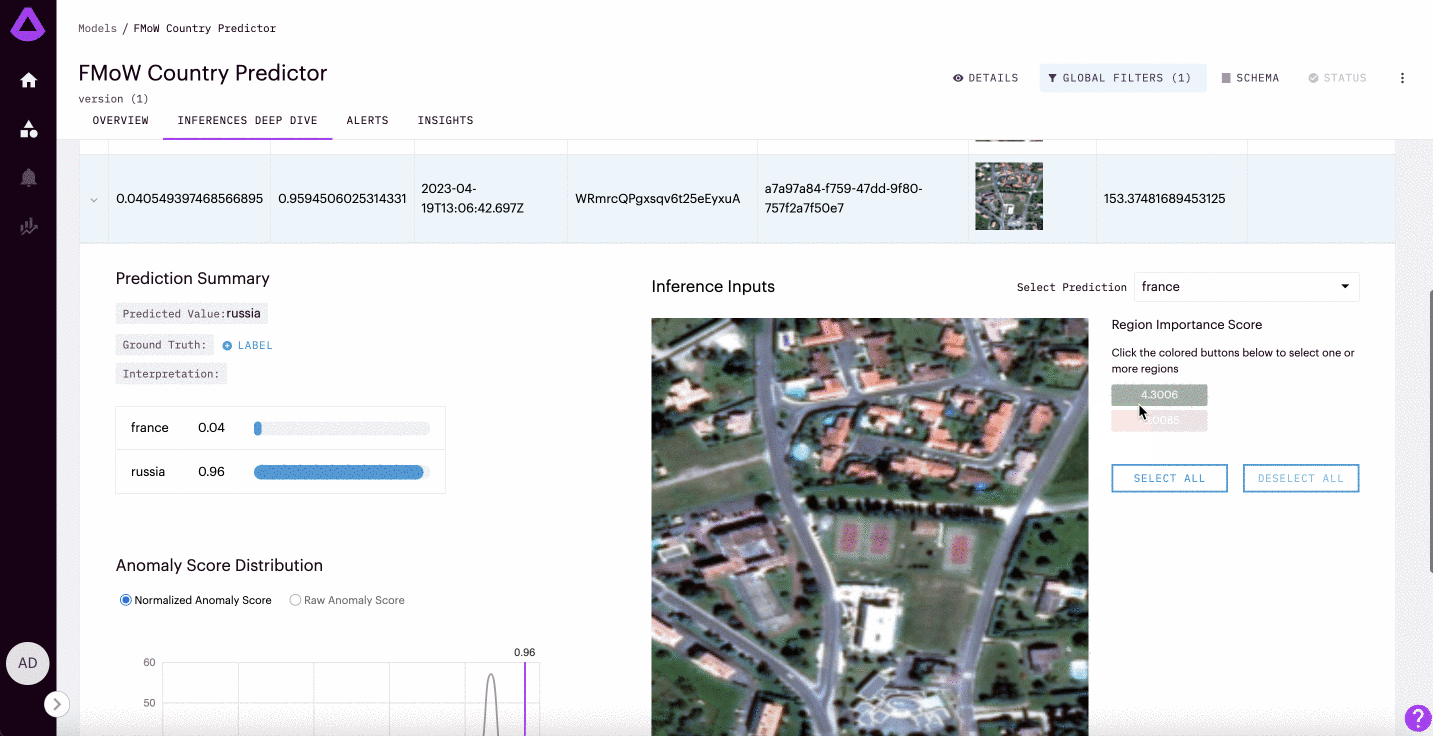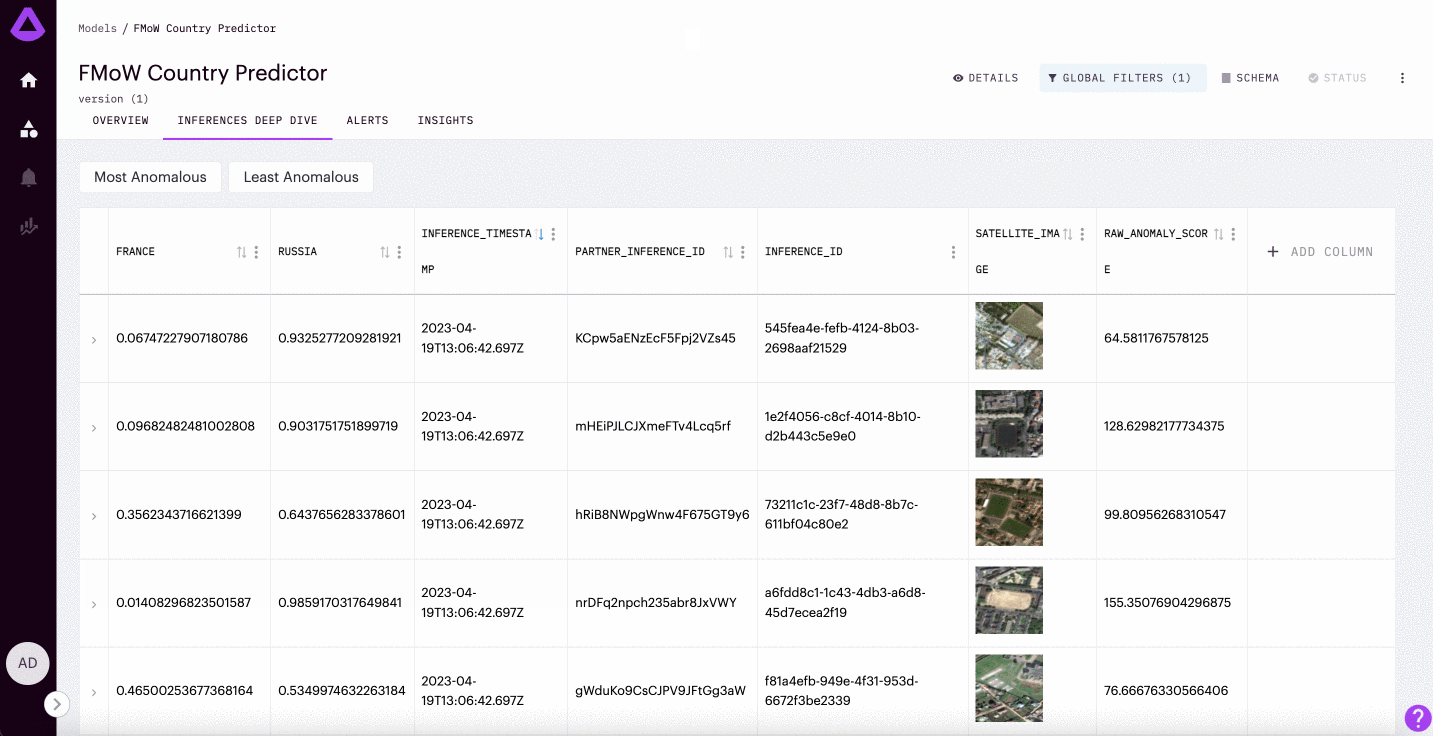
Querying More Levels of Explainability with the Python SDK
Beyond the explainability functionality provided within the UI, many teams choose to pull custom reports or charts with our Arthur Query Service. Common examples can be found here: Querying Explainability
Available Post-Hoc Explainers in Arthur
Arthur supports open-source LIME and SHAP for explainability within the platform.
| Explainer | Available For Tabular Models | Available For Text Models | Available For Image Models |
|---|---|---|---|
| LIME | X | X | X |
| SHAP | X |
Please reference our Enabling Enrichments section in the Model Onboarding section for recommendations regarding which explainer to use.
Available Arthur Schemas
Explainability is available for all model types except Object Detection and Generative Text.
Updated over 1 year ago
Learn more about enabling explainability in general in the enabling enrichments section of Model Onboarding. However, if you are having specific troubles check out our pages on troubleshooting and debugging explainability enablement.