
Data Drift Metrics
Track the stability of your model by comparing real-world data to a reference dataset
Data drift is one of the top causes of model performance decay over time. Data drift measures how much the input data stream to the model changes over time. Tracking data drift over time can help teams identify when models are no longer performing as expected and take proactive steps to maintain or improve their performance. Teams use data drift to illuminate and debug issues like:
- Upstream data issues, such as a third-party data provider changing their tagging of missing data from
nullto -1 - Data quality issues, such as a faulty sensor tagging a feature 10x lower
- Natural demographic shifts, such as an interesting segment of new users from a younger age group using your platform
- Sudden changes in relationships, such as the covid-19 pandemic, immediately shift relationships between features and predictions
Selecting Samples For Comparison
Data drift metrics are essentially metrics built to compare two samples of the same data distribution. It calculates how much that distribution drifts from one sample to another. This section talks about choosing those two samples of comparison.
Using a Reference Dataset
The reference dataset is a representative sample of the input features your model ingests. It is used to compute baseline model analytics. By capturing the data distribution you expect your model to receive, Arthur can detect, surface, and diagnose data drift before it impacts results.
More information about reference datasets can be found in the documentation
- Examples of how reference data is structured for different model types can be found in the Model Input / Output Types section.
- Best practices for selecting a reference dataset can be found in theCreating An Arthur Model Object section
Comparing Points in Time
While the Arthur UI is designed to compare production data against a reference dataset, Arthur can compare any two distribution samples. One of the most popular ways teams use this is by comparing two samples of production data to one another (i.e., how has data from one week, one month, or one quarter ago drifted compared to now). An example of this query can be seen in Querying Data Drift resource.
Type of Data Drift Metrics
We have established that data drift metrics are a comparison of distributions. Now, we can look at the distributions that ML teams often compare.
Feature Drift
Feature drift (also known as covariate drift) refers to the changes in the distribution of input variables to a machine learning model.
Metrics in Arthur for Feature Drift
Arthur allows teams to decide between the most common metrics for feature drift for easy comparison within the UI.
| Metrics Available |
|---|
PSI |
KLDivergence |
JSDivergence |
HellingerDistance |
HypothesisTest |
Prediction Drift
Prediction Drift tracks the discrepancy of your ML model outputs over time.
Prediction drift as a proxy for concept drift
Teams may be familiar with the different types of distributional drifts that can occur within ML systems, the two most popular being covariate and concept drift. Covariate, known in Arthur as feature drift , refers to the distributions of features going into the model changing. Concept drift refers to a changing relationship between the inputs (features) and outputs (predictions) of the model. While concept drift is best tracked with model accuracy metrics, in situtations where there is not ground truth prediction drift is a common proxy for tracking concept drift. See more in this blog post: https://neptune.ai/blog/concept-drift-best-practices
Metrics in Arthur for Prediction Drift
Since prediction drift is another univariate drift technique, it has all the same options as feature drift for available univariate drift metrics.
| Metrics Available |
|---|
PSI |
KLDivergence |
JSDivergence |
HellingerDistance |
HypothesisTest |
Multivariate Drift (Anomaly Detection)
The previous statistical drift metrics listed for both feature and prediction drift are univariate metrics of data drift. This means they only track one attribute at a time, which is incredibly useful for diagnosing specific issues within a feature. However, sometimes teams want to explore the changing relationships between features. This is the purpose of multivariate drift.
Metrics in Arthur for Multivariate Drift
Currently, in the Arthur platform, Arthur provides one multivariate drift metric based on the average of our model-based anomaly score technique.
| Metrics Available |
|---|
Multivariate Drift |
Using Drift to Drive Action
In practice, data drift is best used as a technique to instigate action within teams. To drive this action, teams have to use different features within Arthur.
Investigating Features in Tabular Models
While data drift is commonly used as a proxy for performance for models that do not receive ground truth soon after the time of prediction (if ever), it is also.
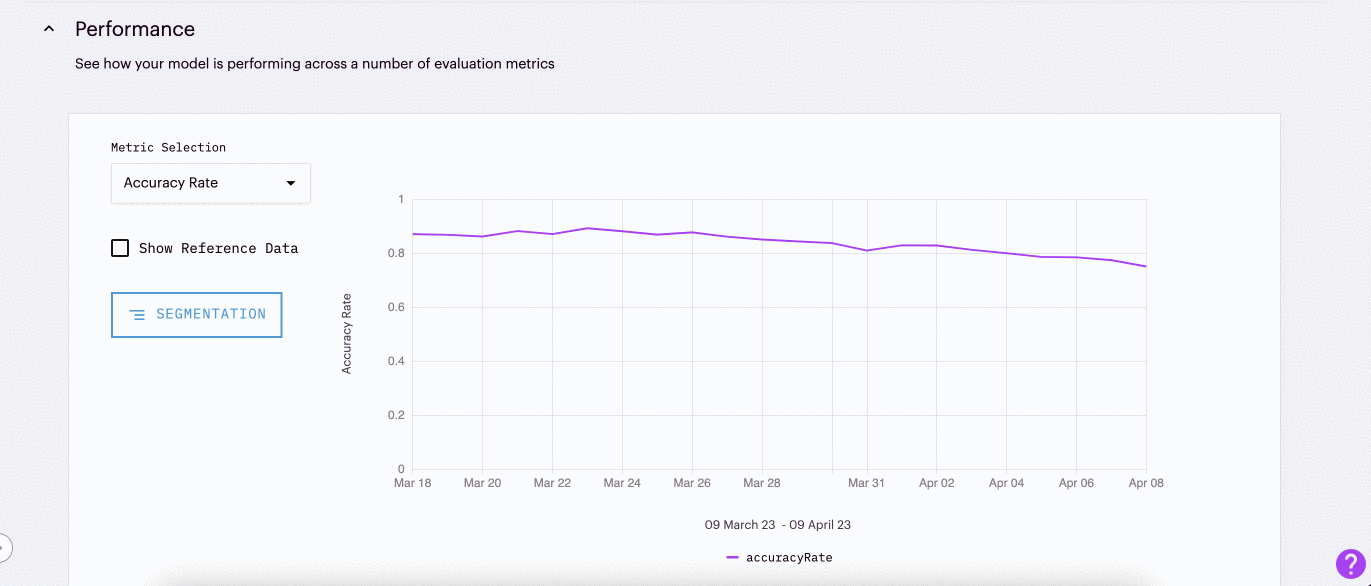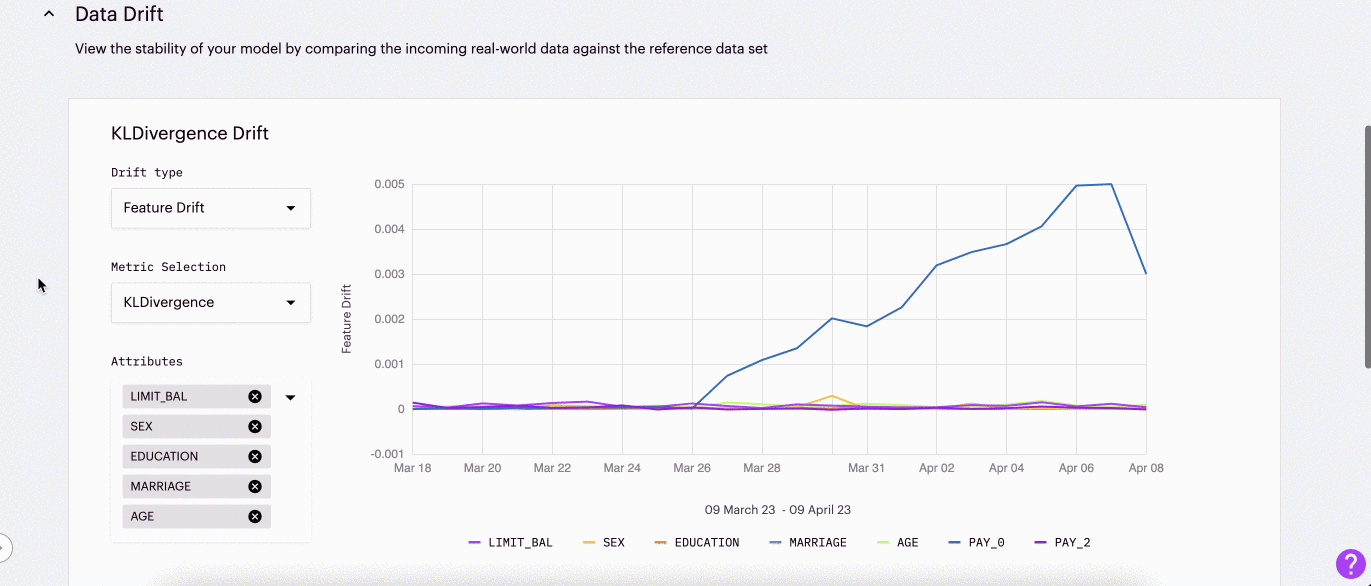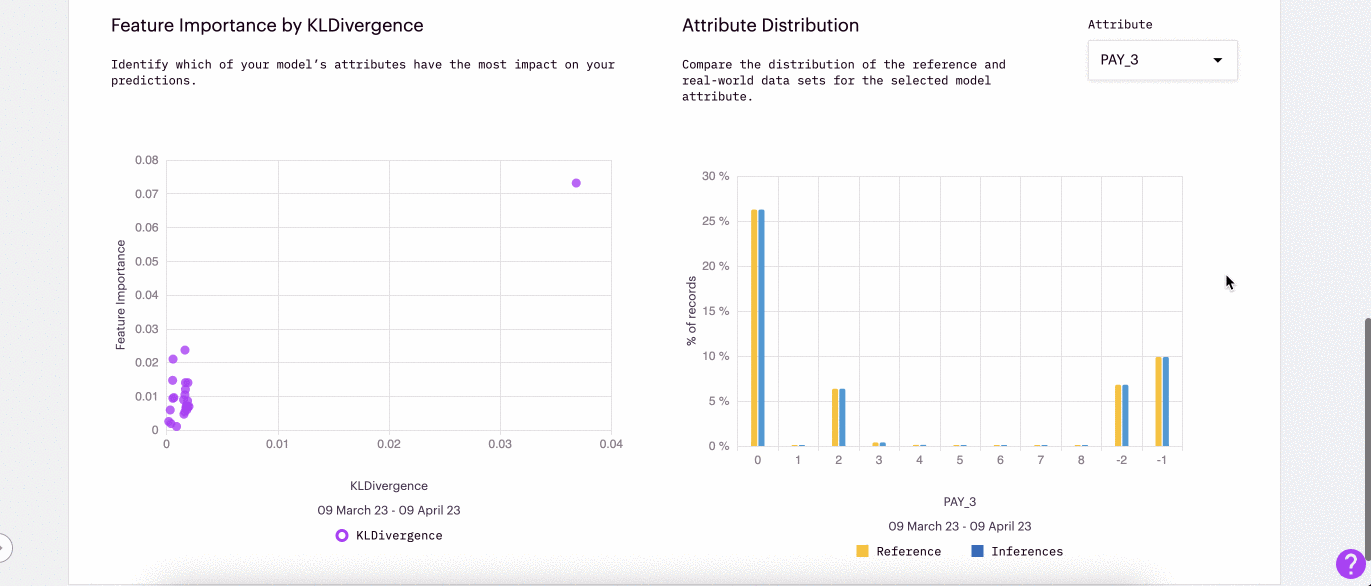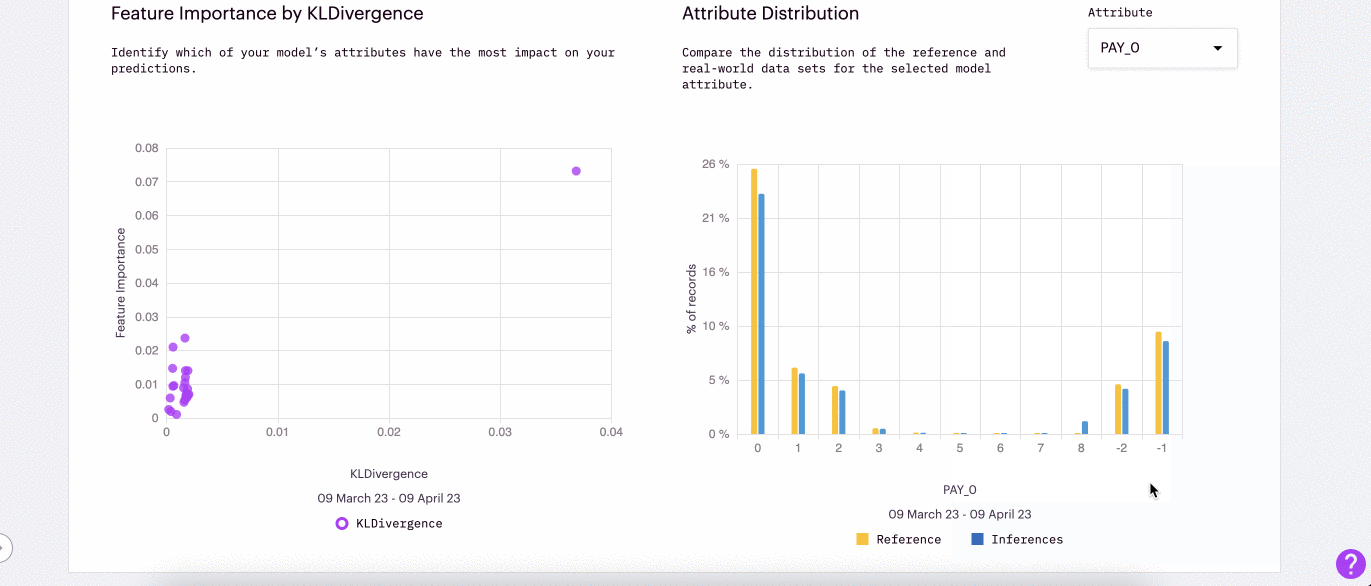
This gif shows an example of how data drift can be used in conjunction with feature importance to track down the root cause of model underperformance.
In the Arthur UI, there are two charts below distributional drift to enable quick evaluation:
Feature Importance x Drift: Using drift in conjunction with feature importance allows teams to understand how impactful drifted features are in modeling predictions
Attribute Distribution: Evaluate the numerical or categorical distributions of the attribute that have drifted to understand the cause of univariate drift.
Anomaly Detection + Multivariate Drift
While univariate drift can be tracked for NonInputData attributes, the most common data distributional drift tracked for Text and Image models is multivariate drift (or anomaly detection). For a more detailed look at how teams use our anomaly detection enrichment to drive value, please refer to the Anomaly Detection page.
Updated over 1 year ago