
Fairness Metrics
Monitor and track fairness metrics in production to take action on underperformance in sensitive segments.
Enabling Fairness Sections
A dedicated fairness section within the UI enables teams to track fairness performance between groups easily. The UI does not infer these trackable groups and must be explicitly defined. For attributes to show up (and be tracked) within the fairness section of the dashboard, they must be enabled for bias monitoring. This can be done with the Python SDK and is further explained in Enabling Enrichments under bias mitigation.
Tracking Fairness in the UI
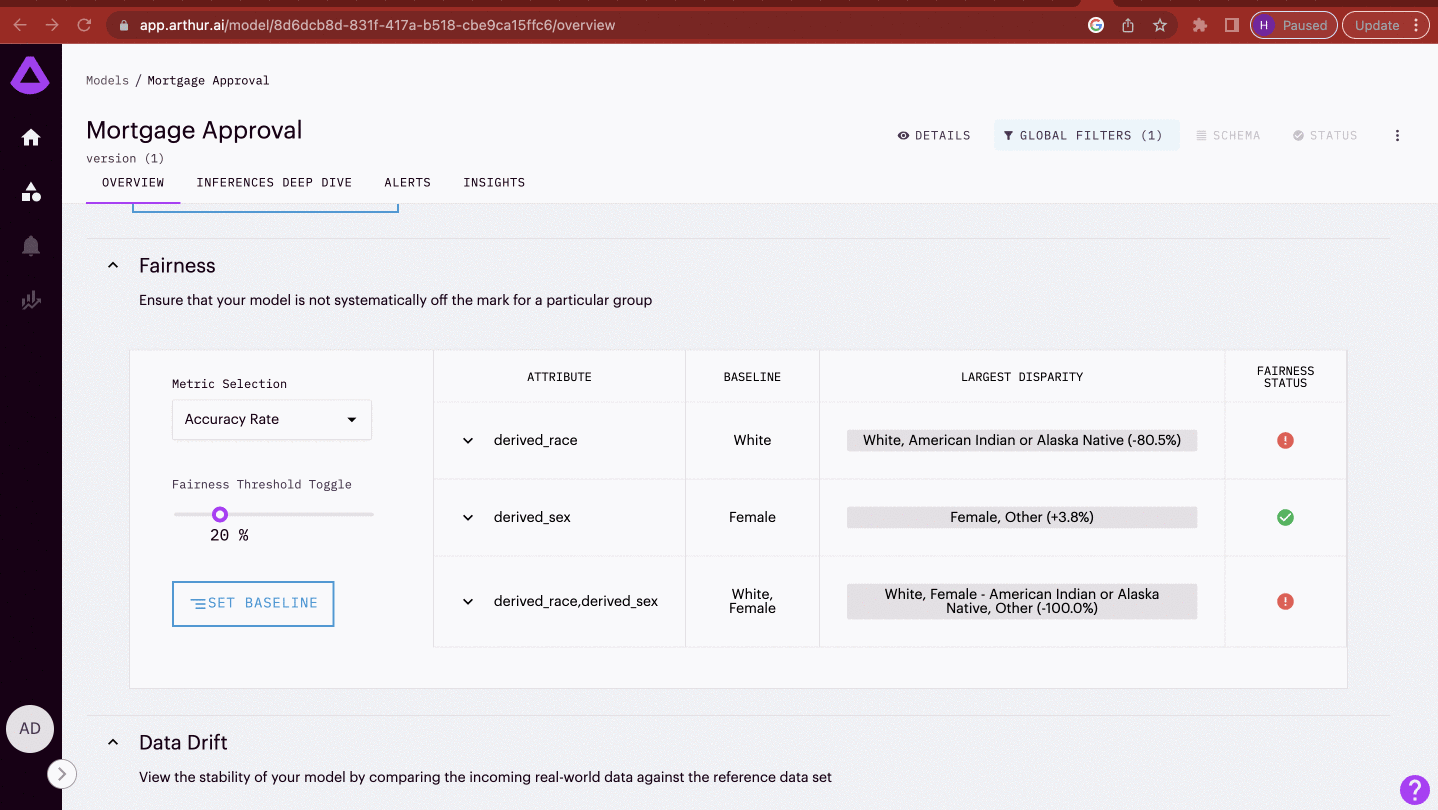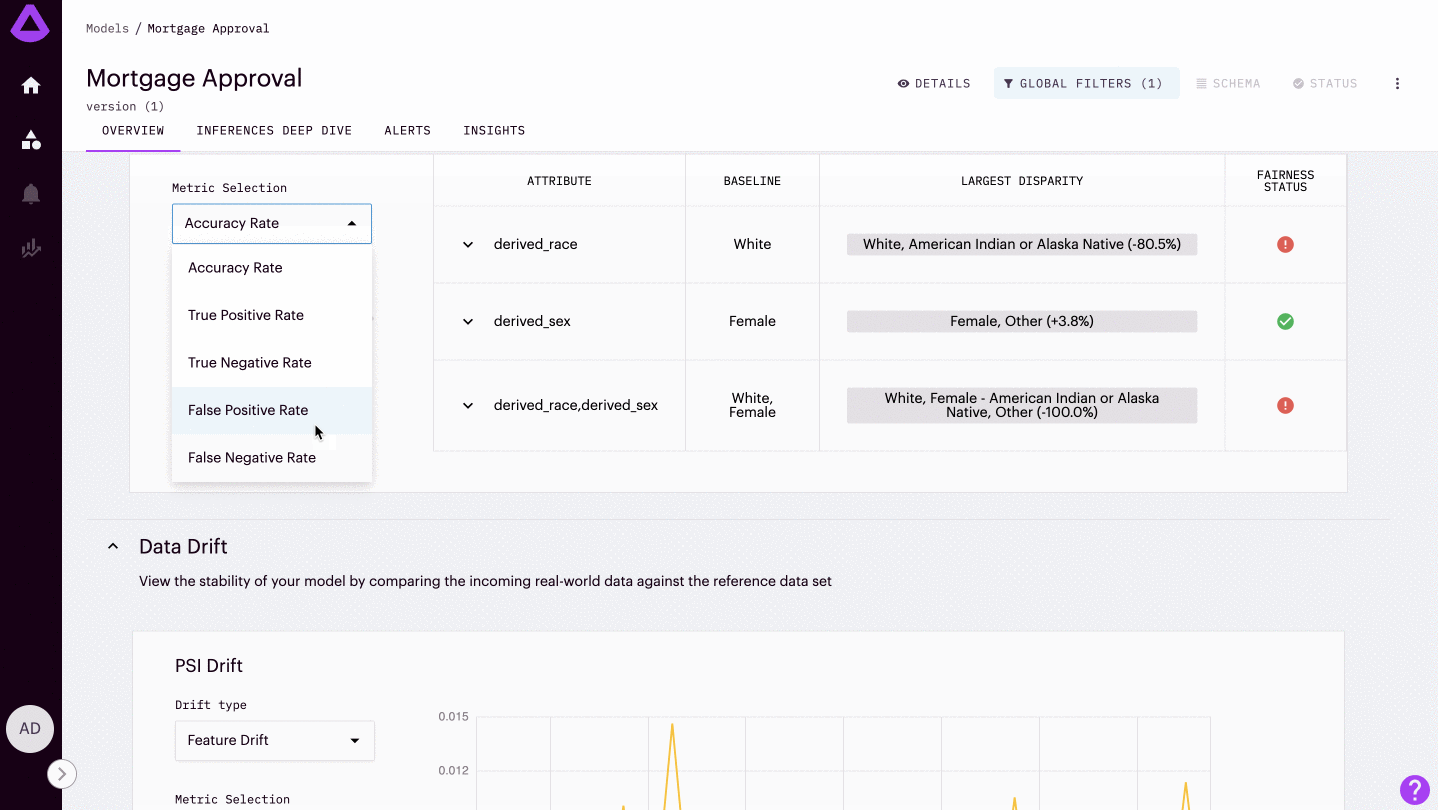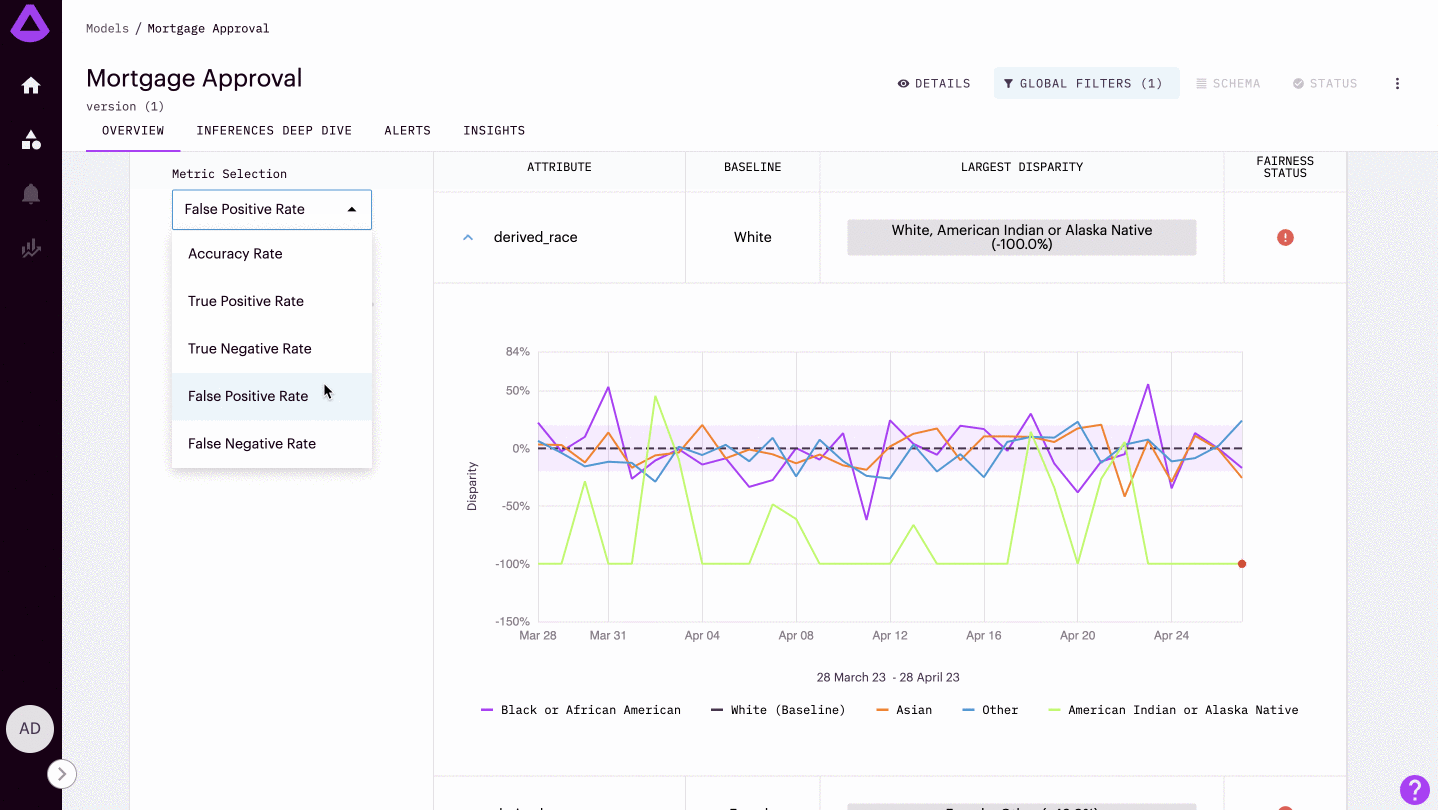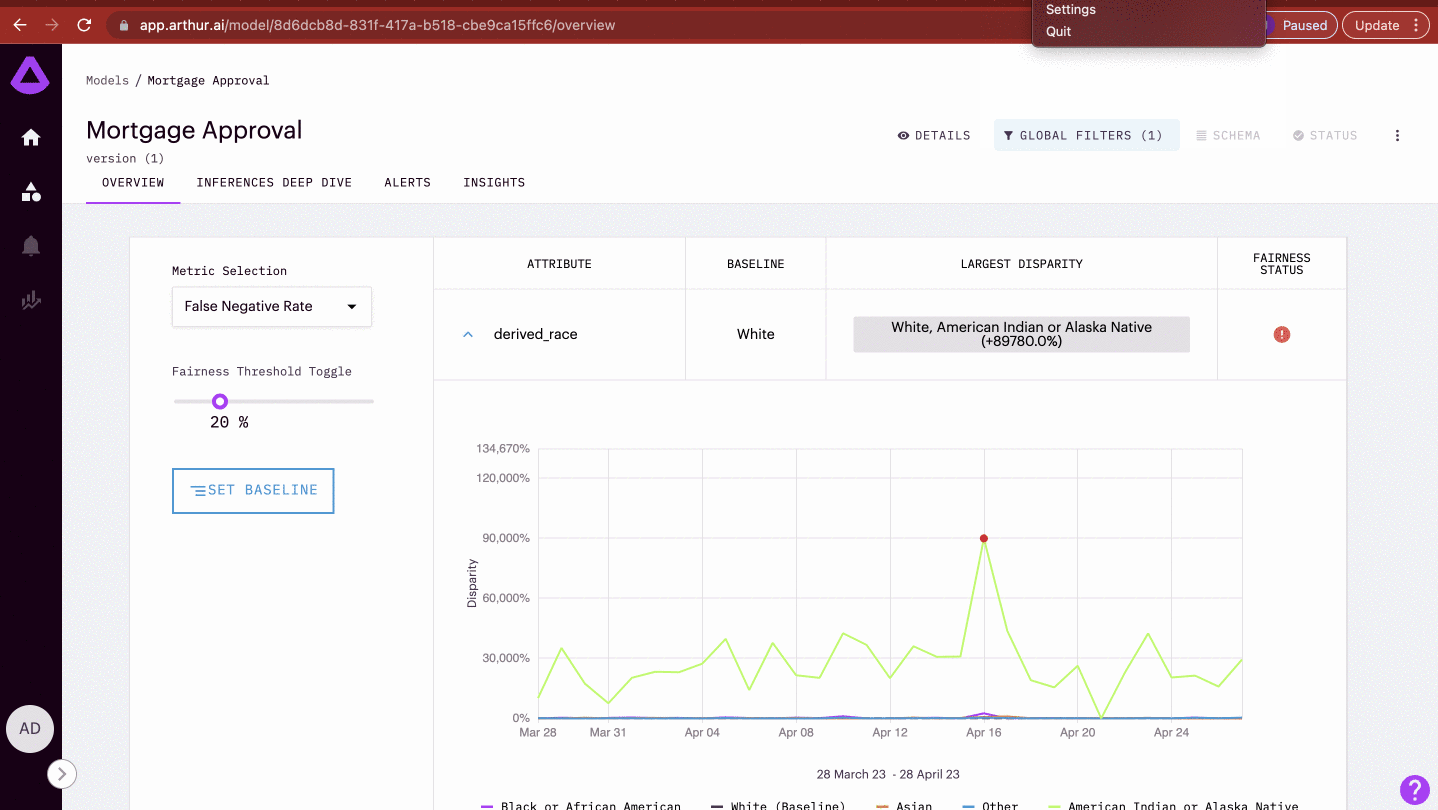
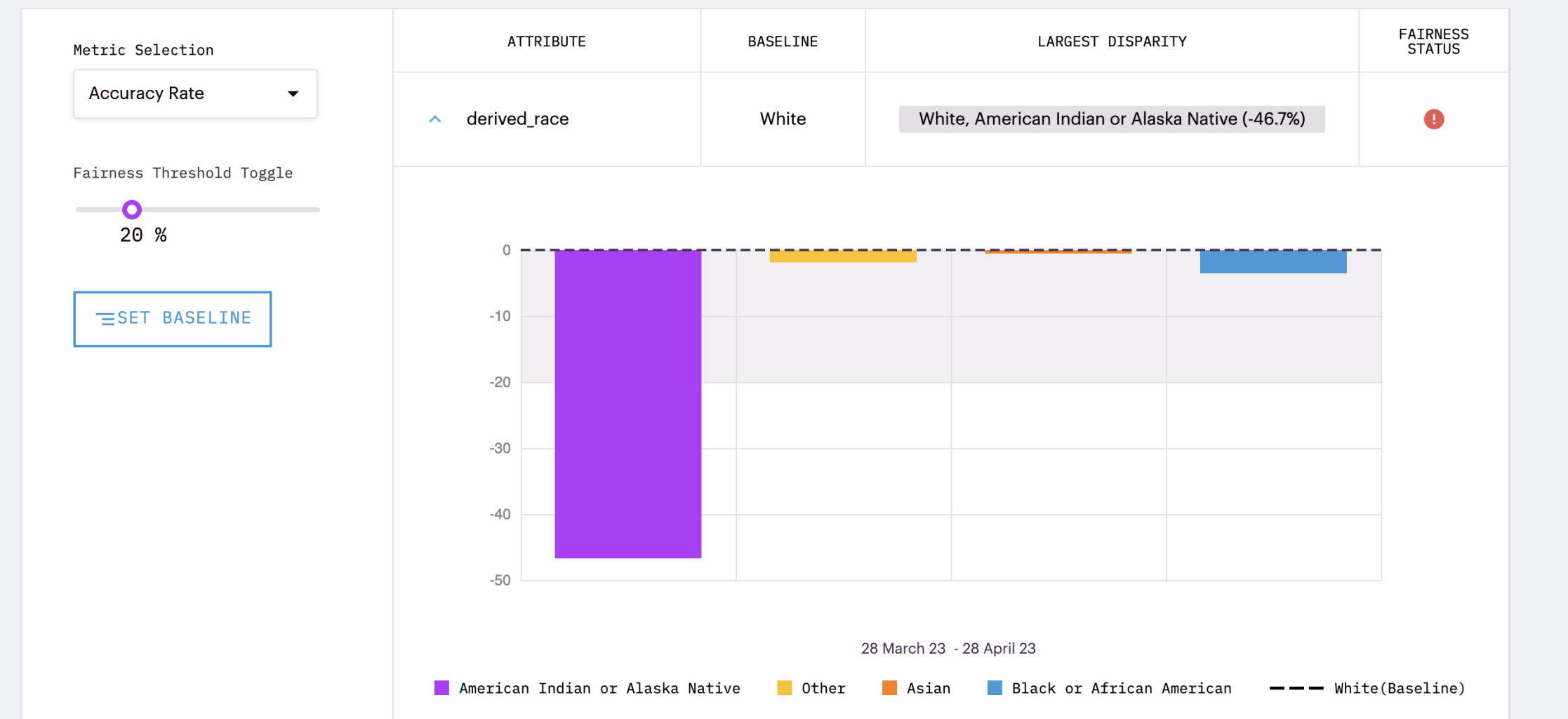
Marked sensitive attributes are tracked in the Fairness section in the model's Overview Tab. This section operationalizes systematic comparisons for critical groups.

Metrics: Easily compare different accuracy rates between groups by selecting from standard fairness metrics within our drop-down selection. These metrics include:
| Metric | Description |
|---|---|
| Accuracy Rate | the proportion of correctly classified instances out of the total number of instances |
| True Positive Rate | the proportion of actual positive instances correctly identified by a machine learning model out of the total number of actual positive instances |
| True Negative Rate | the proportion of actual negative instances correctly identified by a machine learning model out of the total number of actual negative instances |
| False Positive Rate | the proportion of actual negative instances that are incorrectly classified as positive by a machine learning model out of the total number of actual negative instances |
| False Negative Rate | the proportion of actual positive instances incorrectly classified as negative by a machine learning model out of the total number of positive instances |
Baseline: Within Arthur, the fairness section allows comparisons within groups of different attributes of interest. The baseline group is the group that all other groups in that attribute will be compared against. This selection is made by clicking on the Set Baseline button, and the selected group can be seen in the fairness table under the baseline column for each comparison.
Fairness Threshold Toggle: A fairness threshold is the acceptable rate of disparate performance. An appropriate fairness threshold heavily depends on the team and use case, so Arthur does not apply strict parameters. Instead, teams can toggle the threshold to their model's acceptable disparate performance rate.
Fairness Status: Based on the threshold provided, a visual representation of whether a group's performance rate has passed the allowed threshold is provided. A green check represents that all groups' performance for the rate selected is within the threshold compared to the baseline group. On the other hand, red exclamation points mean that one or more comparison groups have points beyond the specified fairness threshold.
Tracking Attribute Disparity
By default, attribute disparity rates are tracked over time.
Using Snap Shot Mode
While tracking performance over time is incredibly helpful for debugging or evaluating when disparate impact occurred, another popular way teams use the fairness section in reporting is with Snapshot mode. Snapshot mode is a toggle at the top of the UI that converts all charts from time series to average bar charts (for the time range selected in the Global Filters). This allows teams to easily create shareable charts for reports on the average impact rate between different groups.
Querying Fairness in a Notebook
Beyond the metrics enabled in the Arthur UI, Arthur can query additional fairness metrics in a notebook. Using the bias metrics submodule, teams can call demographic_parity, group_confusion_matrices, or group_positivity_rates to be calculated on a specified attribute.
arthur_model.bias.metrics.demographic_parity('<attr_name>')
arthur_model.bias.metrics.group_confusion_matrices('<attr_name>')
A description of these bias metrics:
| Metric | Description |
|---|---|
| Demographic Parity | Get group-conditional positivity rates for all inferences, with the option to filter for a batch_id or a particular chunk of time. |
| Group Confusion Matrices | Get group-conditional confusion matrices for all inferences, with the option to filter for a batch_id or a particular chunk of time. |
| Group Positivity Rates | Get group-conditional positivity rates for all inferences, with the option to filter for a batch_id or a particular chunk of time. |
Available Model Types
Since fairness metrics are calculated with accuracy rates, they are only available for classification models within Arthur. Additionally, since fairness metrics are a different visual way of tracking accuracy between sensitive groups, they require ground truth labels.
Updated over 1 year ago