
Querying Explainability
One of the most popular enrichments within Arthur, Explainability values, can also be queried with Arthur's query language. Teams looking to query explainability will pull their values from the enriched table in Arthur. It's important to note that teams must also ensure that explainability has been enabled for their model; otherwise, they will be unable to pull this information.
Tabular Explainability
For tabular models, there are three ways to interact with and query explainability:
- Local Explainability: Explainability is calculated for each inference in a model.
- Global Explainability: This aggregates all inferences' explainability values.
- Regional Explainability: This is a filtered aggregate of explainability values for a specified cohort (or region) of inferences. This is often used for comparison evaluation against the global explainability values or another cohort.
Local Explainability
The most common way to interact with local explainability is within the UI. However, teams that want to pull a local explanation score within a notebook often use the query below. In this query, we are filtering for a specific inference based on itspartner_inference_id, which is the name used for an organization's unique inference id. This is the most common way for teams to look up individual inferences.
query = {
"select": [
{"property": "explainer_algo"},
{"property": "explainer_predicted_attribute"},
{ "property": "explainer_attribute"},
{"property": "explainer_score"}
],
"filter": [
{"property": "[inference_id|partner_inference_id]",
"comparator": "eq",
"value": "<id> [string]"
}
],
"from": "enriched"
}
response = arthur_model.query(query)
[{ "explainer_algo": "lime",
"explainer_attribute": "AGE",
"explainer_predicted_attribute": "prediction_0",
"explainer_score": 0.0016485283063465874},
{"explainer_algo": "lime",
"explainer_attribute": "BILL_AMT1",
"explainer_predicted_attribute": "prediction_0",
"explainer_score": 0.0032036810960691183},
{ "explainer_algo": "lime",
explainer_attribute": "BILL_AMT2",
"explainer_predicted_attribute": "prediction_0",
"explainer_score": 0.002008238656596662},
{ "explainer_algo": "lime",
"explainer_attribute": "AGE",
"explainer_predicted_attribute": "prediction_1",
"explainer_score": -0.0016485283063465892},
{ "explainer_algo": "lime",
"explainer_attribute": "BILL_AMT1",
"explainer_predicted_attribute": "prediction_1",
"explainer_score": -0.0032036810960691126},
{ "explainer_algo": "lime",
"explainer_attribute": "BILL_AMT2",
"explainer_predicted_attribute": "prediction_1",
explainer_score": -0.0020082386565966667} ]
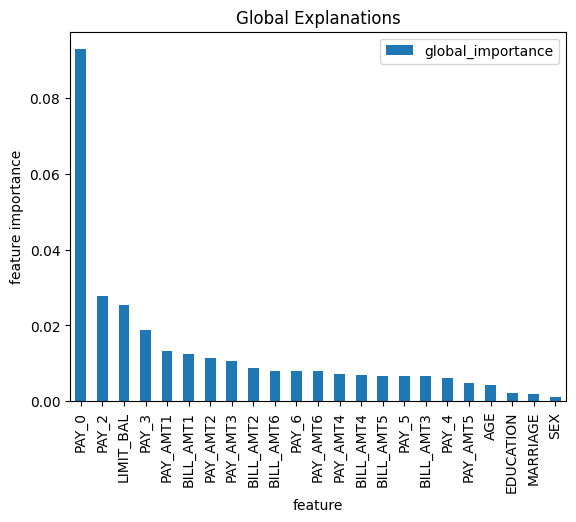
Global Explainability
Global explainability aggregates all the inferences sent to your production model. It is calculated by taking each inference's average value of all feature importance scores. Teams can pull this information using the query below:
## get global explanations
explanation_algo = model.explainability.explanation_algo
predicted_class_col = model.get_positive_predicted_class()
global_explanations = pd.DataFrame(model.query({
"select": [
{
"function": "regionalFeatureImportances",
"alias": "global_importance",
"parameters": {
"predicted_attribute_name": predicted_class_col,
"explanation_algorithm": explanation_algo
}
}
]})).rename(columns={'explainer_attribute': 'feature','global_importance':'global_importance'}).sort_values(by='global_importance', ascending=False)
feature global_importance
0 PAY_0 0.092898
1 PAY_2 0.027737
2 LIMIT_BAL 0.025445
3 PAY_3 0.018831
4 PAY_AMT1 0.013233
5 BILL_AMT1 0.012518
6 PAY_AMT2 0.011359
7 PAY_AMT3 0.010639
8 BILL_AMT2 0.008891
9 BILL_AMT6 0.008058
10 PAY_6 0.007976
11 PAY_AMT6 0.007970
12 PAY_AMT4 0.007123
13 BILL_AMT4 0.006892
14 BILL_AMT5 0.006786
15 PAY_5 0.006765
16 BILL_AMT3 0.006730
17 PAY_4 0.006194
18 PAY_AMT5 0.004818
19 AGE 0.004392
20 EDUCATION 0.002111
21 MARRIAGE 0.001940
22 SEX 0.001188
Teams also often choose to plot these values using this plot function:
ax = global_explanations.set_index('feature').plot(kind='bar')
ax.set_title("Global Explanations")
ax.set_ylabel("feature importance")
Regional Explainability
Regional explainability is similar to global explainability, with additional filters applied to define your region or cohort of interest. This can be seen in the example below:
Query Request:
model.query({
"select": [
{
"function": "regionalFeatureImportances",
"alias": "global_importance",
"parameters": {
"predicted_attribute_name": predicted_class_col,
"explanation_algorithm": explanation_algo
}
}
],
"filter": [
{
"property": "AGE",
"comparator": "gte",
"value": 18
},
{
"property": "AGE",
"comparator": "lt",
"value": 40
}
]
})
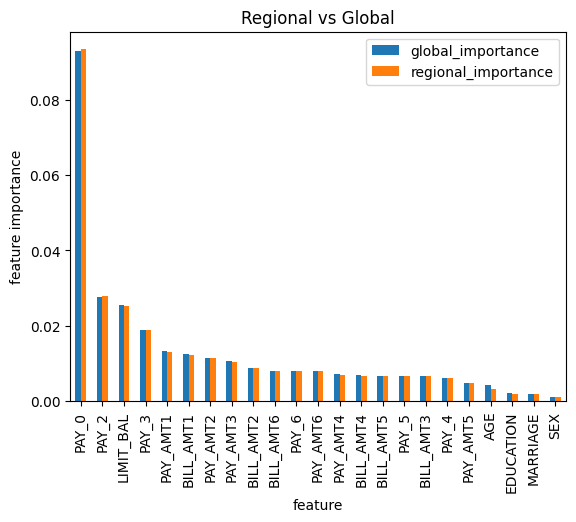
Comparing Regional Importance to Global Importance
def regional_compare_global_explainability(model, regional_filters,title):
## get model attributes
explanation_algo = model.explainability.explanation_algo
predicted_class_col = model.get_positive_predicted_class()
## get regional explanations from filters
regional_explanations = pd.DataFrame(model.query({
"select": [
{
"function": "regionalFeatureImportances",
"alias": "global_importance",
"parameters": {
"predicted_attribute_name": predicted_class_col,
"explanation_algorithm": explanation_algo
}
}
],
"filter": regional_filters
})).rename(columns={'explainer_attribute': 'feature','global_importance':'regional_importance'}).sort_values(by='regional_importance', ascending=False)
## get global explanations
global_explanations = pd.DataFrame(model.query({
"select": [
{
"function": "regionalFeatureImportances",
"alias": "global_importance",
"parameters": {
"predicted_attribute_name": predicted_class_col,
"explanation_algorithm": explanation_algo
}
}
]})).rename(columns={'explainer_attribute': 'feature','global_importance':'global_importance'}).sort_values(by='global_importance', ascending=False)
## combine dataframes
explanations = global_explanations.merge(regional_explanations, left_on='feature', right_on='feature')
ax = explanations.set_index('feature').plot(kind='bar')
ax.set_title(title)
ax.set_ylabel("feature importance")
## Running Regional Explainability
filters = [
{
"property": "AGE",
"comparator": "gte",
"value": 18
},
{
"property": "AGE",
"comparator": "lt",
"value": 40
}
]
regional_compare_global_explainability(arthur_model, filters,title ="Regional vs Global")
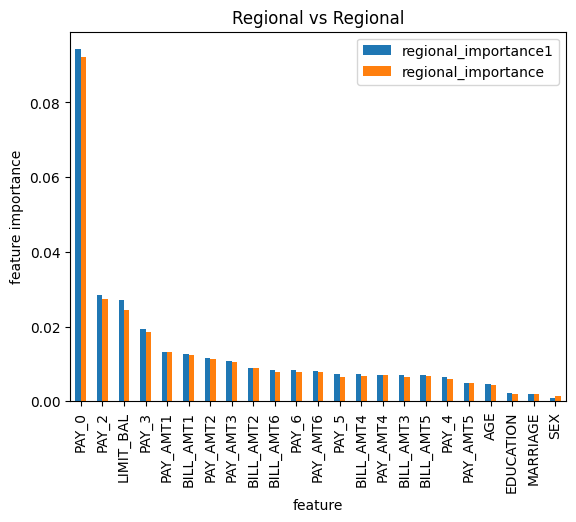
Comparing Regional Importance to Regional Importance
def regional_compare_regional_explainability(model, regional_filters1,regional_filters2,title):
## get model attributes
explanation_algo = model.explainability.explanation_algo
predicted_class_col = model.get_positive_predicted_class()
## get regional explanations from filters
regional_explanations1 = pd.DataFrame(model.query({
"select": [
{
"function": "regionalFeatureImportances",
"alias": "global_importance",
"parameters": {
"predicted_attribute_name": predicted_class_col,
"explanation_algorithm": explanation_algo
}
}
],
"filter": regional_filters1
})).rename(columns={'explainer_attribute': 'feature','global_importance':'regional_importance1'}).sort_values(by='regional_importance1', ascending=False)
## get regional explanations from filters
regional_explanations2 = pd.DataFrame(model.query({
"select": [
{
"function": "regionalFeatureImportances",
"alias": "global_importance",
"parameters": {
"predicted_attribute_name": predicted_class_col,
"explanation_algorithm": explanation_algo
}
}
],
"filter": regional_filters2
})).rename(columns={'explainer_attribute': 'feature','global_importance':'regional_importance'}).sort_values(by='regional_importance', ascending=False)
## combine dataframes
explanations = regional_explanations1.merge(regional_explanations2, left_on='feature', right_on='feature')
ax = explanations.set_index('feature').plot(kind='bar')
ax.set_title(title)
ax.set_ylabel("feature importance")
## Running Regional Explainability
filters1 = [
{
"property": "SEX",
"comparator": "eq",
"value": 1
}
]
filters2 = [
{
"property": "SEX",
"comparator": "eq",
"value": 2
}
]
regional_compare_regional_explainability(arthur_model, filters1,filters2,title ="Regional vs Regional")
NLP Explainability
The nlp_explanation function can be used to query and filter explanations for tokens in NLP inferences. Using this function, the user can filter and order tokens by importance. The following are available optional properties:
nlp_explanation.token- References a token within a specific inference.nlp_explanation.location- References a token's absolute location within a specific inference.nlp_explanation.value- References a token's explanation value within a specific inference.
Query Request:
{
"select": [
{
"function": "nlp_explanation",
"alias": "<alias_name> [Optional]",
"parameters": {
"attribute_name": "<text_input_attribute_name> [string]",
"nlp_predicted_attribute": "<predicted_attribute_name> [string]",
"nlp_explainer": "[lime|shap]"
}
}
],
"filter": [
{
"property": "nlp_explanation.token",
"comparator": "eq",
"value": "<token>"
},
{
"property": "nlp_explanation.location",
"comparator": "eq",
"value": "<location>"
}
],
"order_by": [
{
"property": "nlp_explanation.value",
"direction": "desc"
}
]
}
Query Response:
{
"query_result": [
{
"inference_id": "<id> [string]",
"nlp_explanation": [
{
"algorithm": "[lime|shap]",
"predicted_attribute_name": "<predicted_attribute_name> [string]",
"importance_scores": [
{
"attribute_name": "<input_attribute_name> [string]",
"tokens": [
{
"token": "<token> [string]",
"position": "<position_in_text> [int]",
"value": "<explanation_score> [float]"
}
]
}
]
}
]
}
]
}
Updated over 1 year ago