
Restoring the Arthur Platform
This document details restoring various Arthur platform components from existing backups.
Restore RDS Postgres
Use the AWS RDS documentation to restore the database from an existing RDS Snapshot.
Please ensure that you correctly match the following configuration of the DB from which the snapshot was taken:
- The connection port
- The VPC and Security Group IDs
- DB Subnet Group
- DB Instance Type
- Any other configuration which might be overridden
This operation might take a while, and the DB must show as Available before proceeding to install the platform.
Install the Arthur Platform
Ensure Database is Ready
Only proceed to installing the Arthur platform AFTER the restored database shows as "Available" in the RDS Console.
Install the Arthur platform either using the Airgap Kubernetes Cluster (K8s) Install` or Online Kubernetes Cluster (K8s) Install. Although most configurations for the Arthur platform should remain the same, the following two configurations might need to be updated:
- The "Meta Database" section of the Admin Console should point to the newly restored DB instance.
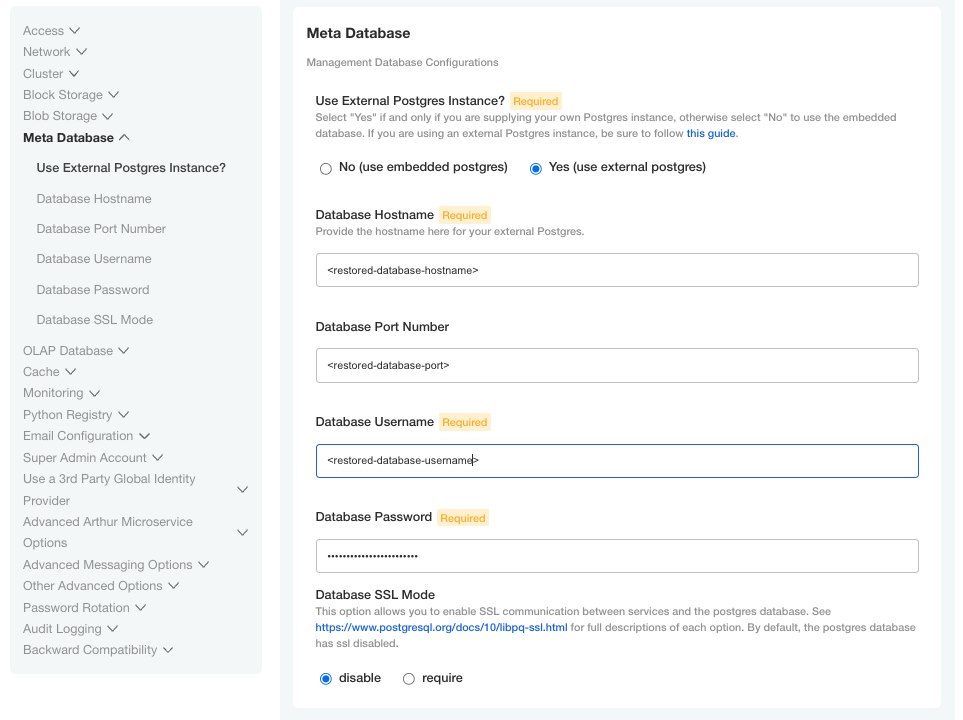
Ensure restore cluster is pointing to the right location
It is very critical to update the configuration to point to the newly restored DB Instance. Failure to complete this step WILL CAUSE DATA CORRUPTION.
-
Update the ingress URL in the "Network" section of the Admin Console.
Wait for the platform to come back online before proceeding to the next steps. All Deployments and StatefulSets should be completely stood up (eg: all Pods should be ready and "Running") and all Jobs should be "Completed".$ arthur_namespace="Put your Arthur namespace here" $ kubectl get pods -n $arthur_namespace NAME READY STATUS RESTARTS AGE argo-workflows-server-75fc4d9d55-wfsqc 1/1 Running 0 12h argo-workflows-workflow-controller-7b95b66b94-66hrs 1/1 Running 0 119m arthurai-alert-service-858784dd7f-4kgq2 1/1 Running 0 4h58m arthurai-api-service-7fc58f4958-trcvg 1/1 Running 0 4h58m arthurai-custom-hpa-646bb978dd-t9b68 1/1 Running 0 12h arthurai-dataset-service-86c8dd54cc-bwwtr 1/1 Running 0 4h58m arthurai-frontend-78cc85fbc5-ffx79 1/1 Running 0 12h arthurai-frontend-beta-5cb8756f68-8hljq 1/1 Running 0 12h arthurai-frontend-classic-5ff79bd579-rhqv8 1/1 Running 0 12h arthurai-ingestion-service-5f7896bf5c-jxwvk 1/1 Running 0 12h arthurai-ingestion-service-5f7896bf5c-vzdn2 1/1 Running 0 4h58m arthurai-kafka-connect-monitor-54cfcc8f7d-dcgr6 1/1 Running 2 12h arthurai-metric-service-78f85cb548-s65dj 1/1 Running 0 12h arthurai-query-service-64d7c9f846-h2ms9 1/1 Running 0 2d12h arthurai-schema-service-69b8c484bd-thhkr 1/1 Running 0 4h58m cache-master-0 1/1 Running 0 12h cache-slave-0 1/1 Running 0 17h cache-slave-1 1/1 Running 0 119m chi-olap-installation-arthur-0-0-0 2/2 Running 0 119m chi-olap-installation-arthur-0-1-0 2/2 Running 0 12h chi-olap-installation-arthur-0-2-0 2/2 Running 0 17h database-primary-0 1/1 Running 0 12h database-read-0 1/1 Running 0 17h database-read-1 1/1 Running 0 119m kafka-exporter-744dbd8476-wwztw 1/1 Running 0 45h kotsadm-5db494c84f-b9vtq 1/1 Running 0 119m kotsadm-minio-0 1/1 Running 0 17h kotsadm-rqlite-0 1/1 Running 0 12h messaging-0 2/2 Running 0 17h messaging-1 2/2 Running 2 11h messaging-2 2/2 Running 0 119m messaging-connect-5db8c6fbcf-jk7st 2/2 Running 0 45h messaging-connect-5db8c6fbcf-jstq7 2/2 Running 0 119m messaging-cp-zookeeper-0 3/3 Running 0 17h messaging-cp-zookeeper-1 3/3 Running 0 2d11h messaging-cp-zookeeper-2 3/3 Running 0 119m messaging-schema-registry-7c646d8c7-mxshj 2/2 Running 0 2d12h messaging-schema-registry-7c646d8c7-q77bh 2/2 Running 0 119m messaging-schema-registry-7c646d8c7-z5s4v 2/2 Running 0 45h olap-installation-zookeeper-0 3/3 Running 0 2d12h olap-installation-zookeeper-1 3/3 Running 0 17h olap-installation-zookeeper-2 3/3 Running 0 119m olap-operator-7999d4fdb8-kkprt 2/2 Running 0 119m $ kubectl get jobs -n $arthur_namespace NAME COMPLETIONS DURATION AGE arthurai-additional-images-bootstrap-xmmes 0/1 16s 16s arthurai-api-key-bootstrap-cfrhy 0/1 16s 16s arthurai-database-migration-hhlpc 0/1 16s 16s arthurai-default-entities-bootstrap-lddho 0/1 15s 16s arthurai-meter-events-connector-deploy-xvxgz 0/1 15s 15s arthurai-model-health-score-connector-deploy-qhvg1 0/1 15s 15s arthurai-query-service-migration-17ehe 0/1 15s 15s clickhouse-v23-migration-job-xynkq 0/1 15s 15s messaging-config-031e7f1c 0/1 15s 15s
Restore ClickHouse Data
The Arthur Platform ships with a Kubernetes CronJob that executes a ClickHouse restore that is scheduled never to run.
To restore ClickHouse data, execute the following commands:
-
Get the name of the clickhouse-backup that coincides with the
kafka/enrichments/workflowbackups that you are restoring- Using the clickhouse pod itself -
$ arthur_namespace="Put your Arthur namespace here" $ kubectl exec chi-olap-installation-arthur-0-0-0 -n $arthur_namespace -c backup -- clickhouse-backup list <<<output-truncated-for-brevity>>> 2023/05/12 15:12:16.199434 info SELECT * FROM system.macros logger=clickhouse chi-olap-installation-arthur-0-0-arthur-clickhouse-backup-2023-05-11-00-00-07 10.33MiB 11/05/2023 00:00:14 remote tar, regular chi-olap-installation-arthur-0-1-arthur-clickhouse-backup-2023-05-11-00-00-07 10.33MiB 11/05/2023 00:00:15 remote tar, regular chi-olap-installation-arthur-0-2-arthur-clickhouse-backup-2023-05-11-00-00-07 10.33MiB 11/05/2023 00:00:15 remote tar, regular chi-olap-installation-arthur-0-0-arthur-clickhouse-backup-2023-05-12-00-00-06 10.33MiB 12/05/2023 00:00:14 remote tar, regular chi-olap-installation-arthur-0-1-arthur-clickhouse-backup-2023-05-12-00-00-06 10.33MiB 12/05/2023 00:00:14 remote tar, regular chi-olap-installation-arthur-0-2-arthur-clickhouse-backup-2023-05-12-00-00-06 10.33MiB 12/05/2023 00:00:15 remote tar, regular 2023/05/12 15:12:18.317324 info clickhouse connection closed logger=clickhouse - Using AWS S3 CLI -
$ aws s3 ls s3://<s3-bucket-name>/<backup-path>/ --profile AWS_PROFILE PRE chi-olap-installation-arthur-0-0-arthur-clickhouse-backup-2023-05-11-00-00-07/ PRE chi-olap-installation-arthur-0-0-arthur-clickhouse-backup-2023-05-12-00-00-06/ PRE chi-olap-installation-arthur-0-1-arthur-clickhouse-backup-2023-05-11-00-00-07/ PRE chi-olap-installation-arthur-0-1-arthur-clickhouse-backup-2023-05-12-00-00-06/ PRE chi-olap-installation-arthur-0-2-arthur-clickhouse-backup-2023-05-11-00-00-07/ PRE chi-olap-installation-arthur-0-2-arthur-clickhouse-backup-2023-05-12-00-00-06/
- Using the clickhouse pod itself -
-
Extract the ARTHUR_BACKUP_NAME from the backups. The backups are named in the
CLICKHOUSE_NODE_NAME-ARTHUR_BACKUP_NAMEformat. For example,chi-olap-installation-arthur-0-0-arthur-clickhouse-backup-2022-05-12-00-00-06can be parsed into:- Clickhouse node name:
chi-olap-installation-arthur-0-0 - Arthur's backup name:
arthur-clickhouse-backup-2022-05-12-00-00-06
- Clickhouse node name:
-
Create the restore job, and configure it to use the Arthur backup name from above
$ arthur_namespace="Put your Arthur namespace here" $ kubectl create job --from=cronjob/clickhouse-restore-cronjob -n $arthur_namespace -o yaml clickhouse-restore --dry-run=client --save-config > clickhouse-restore.yaml $ backup_name="arthur-clickhouse-backup-2022-05-12-00-00-06" # value extracted in above step $ sed -i -e "s/insert-backup-name-here/$backup_name/" clickhouse-restore.yaml $ cat clickhouse-restore.yaml | grep -C2 "name: BACKUP_NAME" # verify the replacement is correct $ kubectl apply -f clickhouse-restore.yaml -n $arthur_namespace job.batch/clickhouse-restore created
Restore Messaging Infrastructure
The Arthur Platform restores Kafka Deployment State, PersistentVolumes, and PersistentVolumeClaims using Velero.
To restore the messaging infrastructure (Kafka and ZooKeeper), run the following commands:
-
Delete the StatefulSets related to messaging infrastructure that was created while installing the platform
$ arthur_namespace="Put your Arthur namespace here" $ kubectl get sts -n $arthur_namespace | grep -i messaging # there should only be two STSs returned $ kubectl delete sts messaging -n $arthur_namespace $ kubectl delete sts messaging-cp-zookeeper -n $arthur_namespace -
Delete the PersistentVolumeClaims related to messaging infrastructure that was created while installing the platform
$ arthur_namespace="Put your Arthur namespace here" $ kubectl get pvc -n $arthur_namespace | grep -i messaging # the number of PVCs returned depends on your configuration $ kubectl get pvc -n $arthur_namespace | grep -i messaging | awk '{print $1}' | xargs kubectl delete pvc -n $arthur_namespace -
Confirm the PersistentVolumes have automatically been deleted (due to a 'delete' retention policy)
$ arthur_namespace="Put your Arthur namespace here" $ kubectl get pv -n $arthur_namespace | grep -i messaging | wc -l # should return 0If the PersistentVolumes still do not get deleted automatically after a few minutes, delete them manually
$ arthur_namespace="Put your Arthur namespace here" $ kubectl get pv -n $arthur_namespace | grep -i messaging # the number of PVs returned depends on your configuration $ kubectl get pv -n $arthur_namespace | grep -i messaging | awk '{print $1}' | xargs kubectl delete pv -n $arthur_namespace
Make sure restore steps are complete
Do not proceed until the above deletion commands have fully completed. Check with the
kubectl get <resource>commands.
- Get the relevant Velero Backup by using the Velero CLI:
$ velero_namespace="Put your Velero namespace here" $ velero backup get -n $velero_namespace | grep messaging NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR arthur-backup-2023-05-11t15.22.37-04.00-messaging Completed 0 0 2023-05-11 15:22:48 -0400 EDT 27d docs-demo-storage-location app in (cp-kafka,cp-zookeeper) $ velero restore create \ --from-backup "arthur-backup-2023-05-11t15.22.37-04.00-messaging" \ --namespace $velero_namespace
Velero will update the Pod Specs, point to the PVs using the EBS Volume Snapshots, and restore the kubernetes resources associated with Kafka.
- Wait for the messaging infrastructure and Arthur platform to become "Ready"
$ arthur_namespace="Put your Arthur namespace here" $ kubectl kots get apps -n $arthur_namespace SLUG STATUS VERSION arthur ready 3.4.0
Restore Enrichments
The Arthur Platform uses Velero to restore the Enrichments infrastructure and workflows, which will require running 2 separate commands.
Restore Enrichments Infrastructure
To restore the enrichments infrastructure, run the following commands:
$ velero_namespace="Put your Velero namespace here"
$ velero backup get -n $velero_namespace | grep enrichments
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
arthur-backup-2023-05-11t15.25.24-04.00-enrichments Completed 0 0 2023-05-11 15:25:33 -0400 EDT 27d default component in (kafka-mover-init-connector,model_server)
$ velero restore create \
--from-backup "arthur-backup-2023-05-11t15.25.24-04.00-enrichments" \
--namespace $velero_namespace
Restore Enrichments Workflows
Restoring the workflows is a 2-step process:
-
Restore the workflows from the Velero backup
$ velero_namespace="Put your Velero namespace here" $ velero backup get -n $velero_namespace | grep workflows NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR arthur-backup-2022-09-23t11.23.25-04.00-workflows Completed 0 0 2022-09-23 11:24:35 -0400 EDT 27d default <none> $ velero restore create \ --from-backup "arthur-backup-2022-09-23t11.23.25-04.00-workflows" \ --namespace $velero_namespace -
Restore Batch Workflows which are recoverable using an Arthur Admin Endpoint
- In one terminal window, port-forward to the dataset service:
$ arthur_namespace="Put your Arthur namespace here" $ kubectl port-forward -n $arthur_namespace svc/arthurai-dataset-service 7899:80 - In another terminal window, run the following commands:
$ curl -k -XPOST http://localhost:7899/api/v1/workflows/batch/recover {"message":"success"}
- In one terminal window, port-forward to the dataset service:
Smoke Tests and Validation
The restore process is now complete. All data should be restored and consistent from when the backup was taken. Any data sent during or after the backup will need to be re-sent. Perform any validation/smoke tests to ensure that the platform is operating.
Updated over 1 year ago